
Здравствуйте. Меня зовут Ник, я фронтенд разработчик (жидкие аплодисменты). Кроме того, что я пишу код, я преподаю в Школе программистов hh.ru.
Записи наших лекций от 2018-2019 учебного года можно посмотреть на youtube
В этом году у меня была лекция про оптимизацию производительности фронтенда, и я решил превратить ее в текстовый формат. Материал получился большим, так как лекция была длительностью 3 часа. Поэтому получился текстовый альманах.

Вот презентация для тех, кому неохота читать лонгрид, но при этом хочется иметь базовое представление о контенте.
Лонгридом можно пользоваться как справочником, чтобы не читать за один присест. Вот список тем, которые мы затронем:
- Зачем думать о производительности
- FMP, TTI + подробнее в докладе
- Critical render path, DOM, CSSOM, RenderTree
- Шаги по улучшению производительности первой загрузки + подробнее в докладе
Для удобства восприятия я решил разделить статью на две части. Вторая часть будет о таких операциях, как layout, repaint, composite и их оптимизации.
Зачем вообще думать о производительности? Мотивационная часть
0.1 секунда это тот gap, который позволяет
пользователю осознать, что именно его клик мышки, удар по
клавиатуре побудил эти изменения в приложении\интерфейсе.
Кажется, у всех было то неловкое чувство, когда ты сочиняешь
письмо\код\любой другой текст, а интерфейс "за тобой не успевает".
Ты уже пишешь второе слово, а на экране всё еще песочные часы (если
мы про windows) и еле-еле набирается первое. Аналогично и с кликами
на кнопки. Я хочу, чтобы интерфейс мне подсказывал, мол, "окей, я
тебя услышал, ща все будет".
За примером далеко ходить не нужно. Я пользуюсь веб-версией одного
российского почтовика (не будем называть имен) и когда выделяю
письма для их удаления, то бывают большие задержки. И я не понимаю:
то ли я не попал по кнопке", то ли сайт тормознутый. И обычно верно
второе.
Почему 0.1 секунда? Дело в том, что мы замечаем и успеваем
обработать даже куда более ограниченные по времени изменения и наш
мозг находится "в контексте".
В качестве яркого примера посмотрите клип 30
seconds to mars hurricane. Там есть вставки на кадр-два с
текстом не 9:30. Глаз успевает не только осознать вставку, но и
частично определить контент.
1 секунда идеальное время для загрузки сайта. В этому случае серфинг для пользователя воспринимается как что-то очень органичное. Если ваш ресурс готов к работе за 1 секунду вы большой молодец. Как правило, реальность другая.
Давайте посчитаем, что для этого нужно: сетевые издержки, обработка запроса бекендами, походы по микросервисам, в базу данных, шаблонизация, обработка данных на клиенте (к этому мы еще вернемся), загрузка статики, инициализация скриптов. В общем больно.
Поэтому обычно 1 секунда это некий идеал, к которому нужно и можно стремиться, но и голову терять не нужно.
10 секунд если погуглить, на всякую аналитику вроде "среднее время пользователя на сайте" мы увидем число: 30 секунд. Сайт загружающийся 5 секунд убивает 1/6 времени пользователя. 10 секунд треть.
Дальше идут два числа 1 минута и 10 минут. первое идеальное время для того, чтобы пользователь выполнил небольшую задачу на сайте прочитал описание товара, зарегистрировался на сайте и т.д. Почему минута? В наши дни мы не так много тратим время на концентрацию на одной вещи. Как правило наше внимание очень быстро перескакивает с одного на другое. Открыл статью, прочитал десятую часть, дальше коллега мем в телегу отправил, тут триггер зажегся, новости про короновирус, верните мне мой 2007, вот это все. В общем к статье получится вернуться только через час.
Второе же число это пользователь не только выполнил одну небольшую задачу на сайте, но и попытался или решил свою задачу с помощью вашего сайта. Сравнил тарифы, оформил заказ и т.п.
Большие компании даже хорошую аналитику для таких целей имеют:
- Walmart: 1 секунда ускорения + 2% конверсии
- Amazon: 0,1 секунды увеличивает выручку на 1%
- Что-то аналогичное есть у Яндекса (киньте в комментариях ссылку, я потерял)
И последний мотивационный пост в статье от википедии:

Однако достаточно вводной, пора двигаться дальше.
Два извечных вопроса
Давайте запустим lighthouse на hh.ru. Выглядит всё очень не очень (запуск на mobile, на desktop все сильно лучше):

Появляется два традиционных вопроса:
- Кто в этом виноват?
- Что с этим делать?
Хотя первый вопрос я бы заменил на "Как это расшифровать".
Сразу спойлер: картинки "как круто стало в конце не будет. Как
сделать лучше мы знаем. Но есть определенные ограничения.
Давайте разбираться
В первом приближении у нас есть 3 потенциальных сценария:
- Отрисовка страницы (с html от сервера)
- Работа загруженной страницы (клики пользователя и т.д.)
- SPA переходы между страницами без перезагрузки
У пользователя существует два этапа при отрисовке страницы, когда он может частично взаимодействовать с сайтом. И полноценно: FMP (First Meaningful Paint) и TTI (Time to interactive), когда ресурсы загружены, а скрипты проинициализированы:
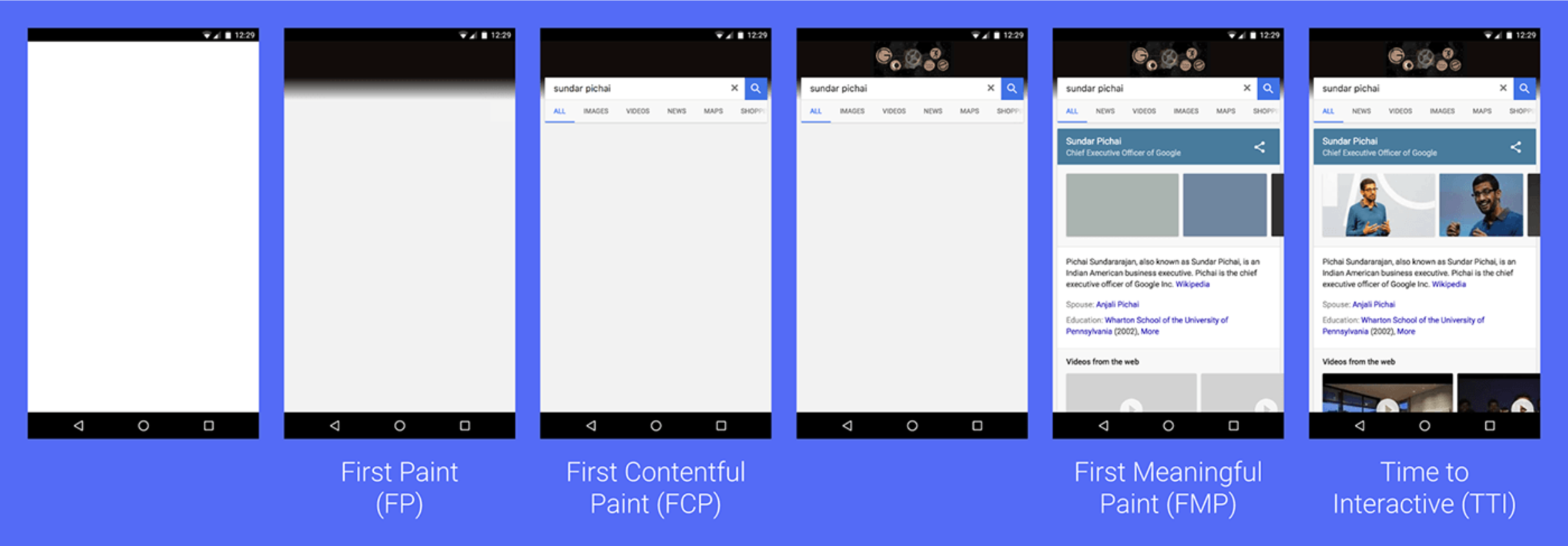
Если судить о значении для пользователя: FMP == текст, есть верстка и пользователь может начать потреблять контент (конечно, если вы не инстаграмм). TTI == сайт готов к работе. Скрипты загружены, проинициализированны, ресурсы загружены.
Подробнее о расчетах FMP\TTI и как мониторить эту информацию на своем сайте, снимая данные с реальных людей, я рассказывал на РИТ++. В этом же докладе я говорил и про эксперименты, которые мы проводили по ускорению и замедлению скорости работы сайта.
Наиболее важный показатель для нас FMP. Соискатели открывают поиск, затем накликивают "открыть в новой вкладке" большое количество вакансий, а затем читают и принимают решение об отклике. C некоторыми оговорками (нюансы рендера браузера) FMP можно воспринимать как одну из основных метрик, которая описывает Critical render path. Critical render path это набор действий и ресурсов, которые браузер должен совершить, загрузить и обработать, чтобы пользователь получил свой первый результат, пригодный для работы. То есть это минимальный набор html, css и блокирующие скрипты (если так еще кто-то делает), без которых сайт не отобразится пользователю.
Critical render path или что браузер делает для того, чтобы пользователь увидел тот самый текст?
TL&DR;
- Сделать запрос (DNS resolve, TCP поход и т.п.);
- Получить HTML-документ;
- Провести парсинг HTML на предмет включенных ресурсов;
- Построить DOM tree (document object model);
- Отправить запросы критических ресурсов. CSS, блокирующий JS (параллельно с предыдущим пунктом);
- Получить весь CSS-код (также запускаем запросы на JS-файлы);
- Построить CSSOM tree;
- Выполнить весь полученный JS-код. Здесь могут вызываться layout, если из js кода происходит форсирование reflow;
- Перестроить DOM tree (при необходимости);
- Построить Render tree;
- Отрисовать страницу (layout paint Composite).
Теперь пройдемся по пунктам отдельно:
Подробно:
Request

Формируем запрос, резолвим DNS, IP, TCP поход, передача запроса и т.п. Байтики бегают по сокетам, сервер получил запрос.
Response
Бекенды зашумели вентиляторами, обработали запрос, записали обратно данные в сокет и нам пришел ответ. Например, вот такой:

Мы получили байты, сформировали из нее строку, основываясь на данных text/html, и после пометки нашего запрос как "navigate" (кому интересно это можно посмотреть в ServiceWorker) браузер должен сформировать из этого html DOM.
Сказано, сделано:
Обработка DOM
DOM
Мы получаем строку или поток данных. На этом этапе браузер парсит и превращает полученную строку в объект:

Это только каркас. Сейчас браузер ничего не знает про стили и про то, каким образом всё это рендерить.
Загрузка блокирующих ресурсов
Браузер будет последовательно обрабатывать полученный html и
каждый ресурс. CSS, JS может быть загружен как синхронно, блокируя
дальнейшую обработку DOM, так и асинхронно (для css это способ с
preload + сменой rel после загрузки на stylesheet). Поэтому каждый
раз, когда браузер будет встречать блокирующую загрузку стилей или
JS, он будет формировать запрос за этим ресурсом.
Для каждого такого ресурса повторяем путь с запросом, ответом,
парсингом ответа. Здесь появляются ограничения, например,
количество одновременных запросов на домен. Предположим, что все
блокирующие запросы были описаны внутри тега head, браузер сделал
запросы, получил нужные для рендера стили. После формирования DOM
переходим к следующему этапу:
CSSOM
Предположим, что помимо meta и title был тег style (либо link). На данном этапе браузер берет DOM, берет CSS, собирает соответствия, и на выходе мы получаем объектную модель для CSS. Выглядит это примерно так:

Левая часть (head) для CSSOM практически не интересна, она не отображается пользователю. А для остальных узлов мы определили стили, которые браузеру нужно применить.
CSSOM важен, так как его понимание позволяет браузеру сформировать RenderTree.
RenderTree
Последний шаг на этапе от формирования деревьев к рендеру.
На этом этапе мы формируем дерево, которое будет рендериться. В нашем примере левая часть дерева, которая включает head, рендериться не будет. Так что эту часть можно опустить:

То есть, именно это дерево мы и отрендерим. Почему его? Если мы зайдем в DevTools там отображается DOM". Дело в том, что, хоть в DevTools и присутствуют все DOM элементы, все расчеты и вычисленные свойства уже основаны на RenderTree.
Проверить крайне легко:

Здесь мы выделили кнопку во вкладке Elements. Мы получили всю
"вычисленную" информацию. Её размеры, положение, стили,
наследование стилей и т.д.
Когда мы получили RenderTree, наша следующая задача выполнить
Layout Paint Composite нашего приложения. После этих трех этапов
пользователь и увидит наш сайт.
Layout Paint Composite могут быть болью не только во время первого
рендера, но и при работе пользователя с сайтом. Поэтому мы разберем
их во второй части статьи.
Что можно сделать, чтобы улучшить метрики FMP и TTI?
TL&DR;
1) Работа с ресурсами:
1.1) Разнести блокирующие ресурсы по страницам. Как js, так и css. Хранить реиспользуемый между страницами код либо в отдельных бандлах, либо в отдельных небольших модулях.
1.2) Грузить то, что пользователю нужно в начале работы со страницей (очень спорный момент!)
1.3) Вынести third-party скрипты
1.4) Грузить картинки лениво
2) HTTP2.0 / HTTP3.0:
2.1) мультиплексинг
2.2) сжатие заголовков
2.3) Server push
3) Brotli
4) Кэш, ETag + Service worker
Подробно:
Работа с ресурсами
Разносим блокирующие ресурсы. JS
Основной болью являются 2 вещи: блокирующие ресурсы и размер
этих ресурсов.
Самый главный совет для больших сайтов это разнести блокирующие
стили, ресурсы по страницам. Реиспользумый код выносить в отдельные
бандлы или модули. Для этого можно воспользоваться условным
loadable-components или
react-imported-component для реакта и похожими решениями для
vue и т.д. Если наши компоненты импортируют стили, то мы сможем
также и разбить стили на отдельные страницы.
На выходе мы получаем:
- бандлы с реиспользуемыми JS модулями
- страничные бандлы.
Стратегией по разбиению кода можно легко управлять. Можно как создавать бандлы, которые объединяют код для нескольких страниц, так и просто страничные и общие. Лучше всего разницу можно посмотреть на схемах.
Изначальная расстановка:
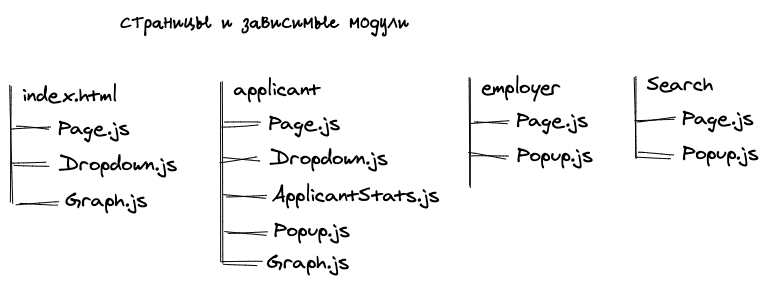
Стратегия 1: делаем зависимость модуль страницы, которые используют модуль
Так, чтобы загрузить главную страницу (index.html), нам нужно
будет загрузить 2 бандла: Common.JS +
applicant+index.JS, а для страницы /applicant нужно
загрузить все 4 бандла. На больших сайтах таких модулей может быть
очень много. В этом случае нам помогает решить эту проблему
использование HTTP2.0.
Итого:
+: Данные распределены между страницами, мы грузим всегда только
необходимое
+: Модули легко кэшируются, после релиза не обязательно обновлять
все бандлы у пользователя
-: Много сетевых издержек для получения отдельных ресурсов. Фиксим
с помощью мультиплексирования HTTP2.0.
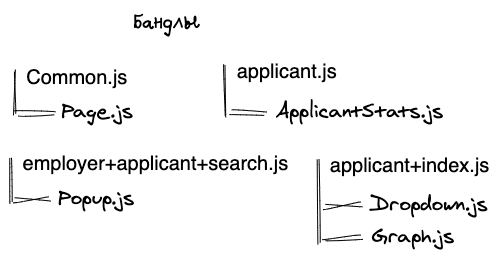
Стратегия 2: реиспользуемые модули хранятся отдельно:

В данном случае каждый файл, который используется больше, чем на одной странице, мы отправляем отдельно. По сравнению с первой стратегией, на средних и больших сайтах мы получаем трагический рост отдельных небольших файлов. Многие из которых будут меньше 1 Кб? что не кэшируется тем же Chrome.
+: Во время релизов большая часть модулей останется в кэше у
пользователя
-: Еще больший рост сетевых издержек, если у пользователя нет
HTTP2.0
-: Кэши могут не работать, так как файлы будут меньше 1 Кб. Здесь
нас может спасти Service worker. О нем будет ниже.
Эта стратегия имеет право на жизнь, так как минусы решаемы.
Стратегия 3: Иметь большой бандл реиспользуемого кода:

+: малое количество бандлов. Для загрузки страницы нужен
страничный JS + Common.JS
-: При первой загрузке мы получаем очень много unused JS
-: При релизе скорее всего пользователю придется скачивать общий
бандл заново, преимущество кэшей теряется.
Я бы рекомендовал либо не использовать этот вариант вообще, либо использовать его для небольших сайтов.
Анти-Стратегия 1: Каждая страница хранит весь список зависимостей, выносим только common:

В данном случае мы получаем большой оверхед. При переходе с одного ресурса на другой пользователь закачивает себе модули, которые уже у него были несколько раз. Например, пользователь заходит на главную и скачивает 2 бандла: Common.JS и Index.JS затем авторизуется и попадает на страницу соискателя. Итого, код для Dropdown.JS и Graph.JS будет скачан дважды.
Пожалуйста, не делайте так :)
Итого
Для больших сайтов я бы рекомендовал использовать одну из первых двух стратегий. Скорее всего это улучшение положительно скажется на вашей TTI метрике. Если же у вас блокирующий JS, то стоит задаться вопросом почему. Должен ли он быть таким? Старайтесь держать как можно меньше блокирующего JS на странице.
Оффтоп. Почему 30 Кб JS это больнее, чем 30 Кб картинки
Предположим у нас есть JS код, который анимирует страницу, добавляет какие-то выпадающие элементы, и есть картинка того же размера.
Для того, чтобы запустить JS нам нужно скачать код, распарсить его, сериализовать в код для компилятора, исполнить.
Итого, на обработку JS кода мы тратим больше времени, чем на ту же картинку.
Разносим блокирующие ресурсы. CSS
Данное улучшение напрямую влияет на FMP, если у вас не
асинхронный CSS.
Если вы используете react\vue\angular, то для стилей стоит сделать
то же, что и в предыдущем пункте. Как правило, в том же react-коде
мы имеем импорты вида:
import './styles.css'
Это значит, что во время бандлинга JS-кода мы можем разделить и
CSS, воспользовавшись одной из стратегий выше. Это поможет вебпаку
или другому бандлеру получить аналогичные common.css,
applicant-page.css и
applicant+employer.css.
Если разбить используемый CSS не получается, можно посмотреть в
сторону used-styles
и статью на эту тему:
"optimising css delivery". kashey
спасибо за клевые инструменты :)
Это поможет ускорить загрузку, например в случае с hh.ru почти на секунду по эстимейтам lighthouse:

Грузим то, что увидит пользователь, а не всю страницу.
Скорее всего на странице пользователь увидит несколько экранов. Я имею в виду, что далеко не всё влезет в первый. Кроме того, часть возможностей будет скрыта под кликами на кнопки.
Идея данной оптимизации в том, чтобы управлять загрузкой ваших
ресурсов. В начале загрузить блокирующим способом тот CSS, который
жизненно необходим для открытия страницы. Весь CSS, который
относится к всплывающим элементам, popup-ам, которые спрятаны под
JS кодом можно будет грузить асинхронно, например, добавив
rel=stylesheet уже из JS кода, либо воспользовавшись
prefetch с onload колбеком.
В данном случае мы усложним разработку, но сможем улучшить наш FMP. Общего совета как это сделать нет, нужно индивидуально смотреть сайт и выяснять, какие элементы можно перевести в асинхронную загрузку.
Выносим third-party скрипты
У нас в hh их много. Очень много!
Например? здесь в ТОП-10 самых тяжелых скриптов 7 third-party.

Что мы можем с этим сделать?
- Убедиться, что все ресурсы грузятся асинхронно и не влияют на FMP.
- Для рекламы и прочих вещей (излишней аналитики, popup-ов
поддержки) снизить их влияние на основной "полезный" код. Это можно
сделать, начав их инициализировать из нашего кода по
requestIdleCallback. Эта функция запланирует вызов колбека с низшим приоритетом, когда наш браузер будет простаивать.
Такой подход позволяет нам экономить на FMP, хотя в TTI мы по-прежнему будем наблюдать проблемы. Это также поможет нам отложить работу прожорливых third-part скриптов.
Грузим картинки лениво
Картинки влияют на ваш TTI. Если вы понимаете, что пользователи из-за лишней работы браузера могут страдать, попробуйте начать грузить картинки, которые не попадают на экран, лениво. То есть:
- Картинки попадающие на первый экран, грузим как обычно
- Оставшимся картинкам проставляем специальные атрибуты, чтобы изображение грузилось только по мере того, как пользователь проскроллит к нему
- Используем любую библиотеку\велосипед для ленивой загрузки картинок. Вот здесь достаточно хорошо описан подход.
HTTP2.0
Многие из пунктов HTTP2.0 могут не сэкономить заметного количества времени, но разобрать их стоит.
HTTP2.0 Мультиплексинг
В случае если сайт загружает большое количество ресурсов,
HTTP2.0 с мультиплексингом может сильно помочь.
Предположим, у нас есть 6 блокирующих ресурсов на домене, которые
нужно скачать, чтобы отобразить сайт. Это могут быть стили или
блокирующий JS. Считаем, что пользователь уже загрузил HTML:

Для отображения контента браузер будет производить параллельные запросы к каждому ресурсу:

В какой-то момент мы можем столкнуться с проблемой: браузеры ограничивают количество одновременных запросов на домен в рамках одной вкладки. Поэтому часть ресурсов будет запрошена после получения ответа от предыдущих блокирующих ресурсов.
Кроме того, каждый из ресурсов будет проходить времязатратные этапы на TCP handshake и прочие издержки. Они небольшие, но все-таки присутствуют.
Именно поэтому совет нужен бандлинг и отдавать пользователю один бандл с нужным ему на этой странице CSS \ JS картинками работает.
Что такое мультиплексирование?
Мультиплексирование позволяет нам грузить ресурсы внутри одного HTTP запроса:

Запросов может быть несколько, и каждый из них грузит небольшое количество ресурсов. Так мы экономим на установлении соединения и оптимизируем ограничение по количеству одновременных запросов.
HTTP2.0 Сжатие заголовков
До http2.0 сжатия заголовков не существовало. В HTTP2.0 был анонсирован HPACK, которые отвечает за сжатие. Здесь можно почитать подробнее.
Иногда заголовки могут занимать значительный объем запроса. О том, как работает сжатие заголовков HPACK вкратце:
Используется два словаря:
- Статический для базовых заголовков
- Динамический для кастомных
Для префиксного кодирования используется Huffman coding. На практике эта экономия выходит не сильно высокой и малозаметной.
HTTP2.0 Server push
В базовом варианте server push реализовать несложно. Проще всего сделать такую штуку для статических сайтов. Идея простая: вместе с запросом html страницы, наш веб-сервер заранее знает, что пользователю нужно отдать такой-то css, такую-то картинку и такой-то JS.
Реализуется достаточно просто (nginx):
location = /index.html { http2_push /style.css; http2_push /bundle.JS; http2_push /image.jpg; }
Проверить, что все работает несложно:

Такой способ будет работать для небольших статических сайтов. Если у вас большой сайт, то придется настраивать сложный пайп-лайн. Когда после сборки имена ваших ресурсов записываются в какой-то словарь, который затем собирает конфиг для nginx, содержащий урлы и прописывает http2_push правила.
Сжатие данных
Наиболее популярными решениями сейчас являются gzip и brotli. Вот сайт, где есть хорошее сравнение степени сжатия двух алгоритмов:

Примерно полтора года назад мы в hh.ru перешли с gzip на бротли. Размер нашего основного бандла уменьшился с 736 КБ до 657. Выиграли почти 12%.
Главным недостатком Brotli можно назвать затраты на "упаковку" данных. В среднем она тяжелее, чем gzip. Поэтому на nginx можно указать правило, чтобы он паковал ресурс и складывал его рядом, дабы не делать сжатие на каждый запрос. Ну или при сборке сразу класть сжатый вариант. Аналогично можно делать и для gzip.
Но в любом случае Brotli ваш бро! На сайтах среднего размера он позволяет сэкономить секунду-полторы загрузки на слабых 3G сетях, что сильно улучшает как пользовательские ощущения, так и метрики в том же lighthouse.
КЭШ
Примечание: описанный здесь способ не поможет вам
получить дополнительные баллы у lighthouse, но поможет при работе с
реальными пользователями. Этот способ положительно сказывается как
на FMP, так и на TTI.
Сам кэш можно включить либо с помощью заголовков у статики, либо с
помощью Service Worker.
Если мы говорим о заголовках, для этого служит 3 основных
параметра:
- last-modified или expires
- ETag
- Cache-control
Первые два (last-modified и expires) работают по дате, второй ETag это ключ, который используется при запросе и если ключи совпадают, сервер ответит 304 кодом. Если не совпадут, то сервер отправит нужный ресурс. Включается на Nginx очень просто:
location ~* ^.+\.(js|css)$ { ... etag on;}
Disk cache проверяется очень просто через dev tools:

Cache-control это стратегия того, как мы будем кэшировать информацию. Мы можем или отключить его вовсе, установив cache-control: no-cache, что может быть полезным для html запросов, которые часто меняются. Либо мы можем указать очень большой max-age, чтобы данные хранились как можно дольше. Для нашей статики, мы устанавливаем вот такой Cache-control:
cache-control: max-age=315360000, public
У нас частые релизы (несколько раз в день релизим каждый
сервис), поэтому код в основном бандле меняется часто. Это приводит
к тому, что пользователям приходится часто скачивать наши бандлы,
парсить код и т.д.
Чтобы больше разобраться в том, как современные браузеры исполняют
код и используют кэши, можно почитать прекрасную статью в блоге
v8
Нам интересна вот эта иллюстрация:

У нас есть "три способа" запуска нашего приложения: cold\warm и hot run. Идеально, если мы будем запускать приложение в режиме hot run, потому что на этом этапе мы не тратим время на компиляцию нашего года. Его достаточно только десериализовать.
Для того, чтобы получить hot run, пользователю нужно зайти на сайт в третий раз (за одними и теми же ресурсами) в таймслоте в 72 часа. В третий потому что во второй раз будет выполнен warm run, который будет компилировать и сериализовать данные в дисковый кэш.
Мы на самом деле можем зафорсить hot run, использовав Service Worker. Механизм следующий:
- Устанавливаем пользователю Service Worker;
- Service worker подписывается на fetch;
- Если происходит fetch за статикой, то сохраняем результат в кэш;
- Добавляем перед отправкой запроса проверку на наличие ресурса в кэше.
Этот подход позволяет нам забустить дисковый кэш и использовать hot run уже со второй загрузки сайта. Дополнительное улучшение перфоманса мы получаем для мобильных устройств, которые чаще сбрасывают свой обычный кэш.
Минимальный вариант кода для данного случая:
self.addEventListener('fetch', function(event) { // Кешируем статику, но не картинки if (event.request.url.indexOf(staticHost) !== -1 && event.request.url.search(/\.(svg|png|jpeg|jpg|gif)/) === -1) { return event.respondWith( // проверяем наличие данных в кеше caches.match(event.request).then(function(response) { if (response) { return response; } // Если данных в кеше нет, делаем запрос и сохраняем данные в кеш, который наызываем cacheStatic return fetch(event.request).then(function(response) { caches.open(cacheStatic).then(function(cache) { cache.add(event.request.url); }); return response; }); }) ); }});
Итого
Мы рассмотрели наш Critical render path с точки зрения клиента (не углубляясь в такие вещи, как резолв DNS, handshake, запросы в БД и т.п.). Определили те шаги, которые делает браузер, чтобы сформировать первую страницу для пользователя. Поверхностно посмотрели на сложные способы оптимизации (разделения контента и т.д.)/ И разобрали более простые способы оптимизации: бандлинг, кэш, сжатие, транспорт.
Во второй части мы разберем работу сайта после загрузки, остановившись подробнее на механизмах перерисовки страницы.
Небольшое уточнение: здесь рассмотрены не все способы
оптимизации, их заметно больше и появляются новые. Например, в
chrome
85 появится свойство content-visibility, которое
позволит сократить время на рендеринг за счет отложенных
вычислений.






































































































































































{kind=link}
{kind=link}