
Привет, Хабр! Меня зовут Станислав Маскайкин, я архитектор
аналитических систем ВТБ. Сегодня я расскажу о том, почему мы
перевели нашу систему подготовки отчётности с Oracle SuperCluster
на российскую Arenadata DB. Как мы выбирали решение, почему не
взяли чистый опенсорс, а также о некоторых результатах такой
миграции под катом.
Зачем нужен был переход?
Несколько лет назад банк ВТБ объединился с Банком Москвы и ВТБ
24. Каждый из банков имел собственную ИТ-инфраструктуру с отдельным
аналитическим контуром. После объединения получилось, что в банке
одновременно существуют три разных ИТ ландшафта.
Само по себе владение тремя разными системами это тройные
затраты на инфраструктуру, поддержку и развитие. Но в нашем случае
было ещё несколько факторов.
С точки зрения законодательства любой банк должен регулярно
сдавать отчётность проверяющим органам. После объединения эту
отчётность мы должны были сдавать уже по единому ВТБ. Имея три
разрозненные системы, решать эту задачу можно было разве что
вручную.
Исторически ВТБ24 был ориентирован на работу с физическими
лицами, ВТБ на работу с юридическими лицами, а Банк Москвы на
работу и с первыми, и со вторыми.
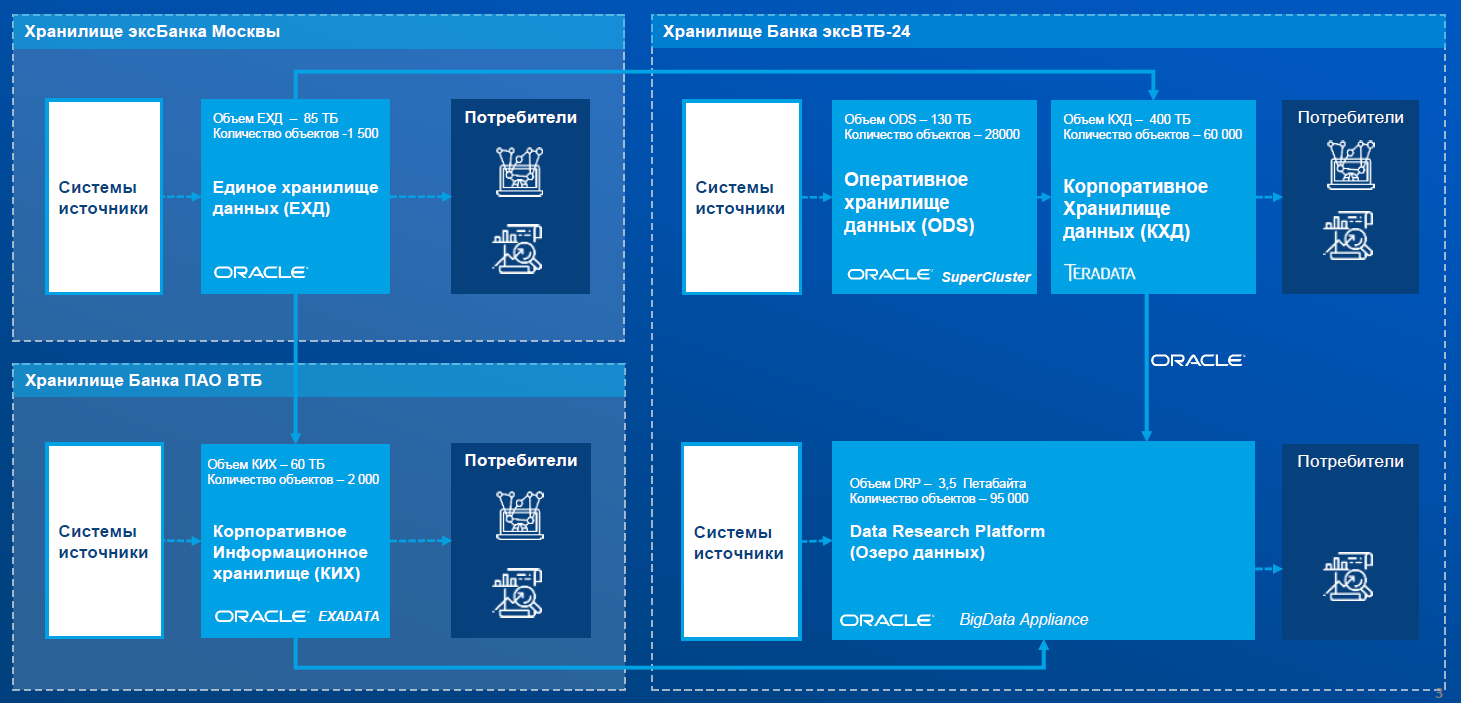
На момент объединения этих банков обязательная отчётность
формировалась в следующих системах:
-
Единое хранилище данных (ЕХД) хранилище данных Банка Москвы,
реализованное на SuperCluster M8 и ETL-инструменте Informatica
Power Center.
-
Система подготовки отчётности хранилище данных ВТБ24,
реализованное на Oracle SuperCluster M8 с программным обеспечением
Diasoft Flextera BI. Данные для этой системы готовились в другом
хранилище корпоративном хранилище данных (КХД), реализованном на
СУБД Teradata и ETL-инструменте SAS Data Integration. КХД, в свою
очередь, получало данные из оперативного хранилища данных,
реализованного на Oracle SuperCluster M8. А туда они
реплицировались из автоматизированных банковских систем при помощи
инструмента Oracle Golden Gate.
-
Корпоративное информационное хранилище хранилище данных ВТБ,
реализованное на Oracle Exadata X8-2 и ETL-инструменте Informatica
Power Center.
Чтобы не формировать обязательную отчётность по объединённому
ВТБ в ручном режиме, были созданы интеграции между хранилищами
данных.
Это привело к ещё двум большим проблемам:
-
Увеличилось время получения данных, что часто приводило к срыву
сроков предоставления информации.
По правилам ЦБ РФ отчётность за очередной месяц сдаётся в
течение первых четырех дней следующего месяца. В банке под это
задействуются огромные вычислительные мощности. Если первые дни
месяца попадают на рабочие дни (как в марте), мы даже не имеем
возможности вернуться и что-то пересчитать это риск для банка не
сдать отчётность вовремя. Повышение доступности данных на этом
уровне играет огромную роль.
-
Из-за большого количества расчётов в хранилищах и копирования
данных выросло количество инцидентов с качеством этих данных, что
тоже очень сильно влияет на сроки предоставление отчётности.
Ещё один момент: многие компоненты нашей инфраструктуры, такие
как Oracle SuperCluster, на котором у нас реализована большая часть
аналитического ландшафта, попали под End of life. Они были сняты с
поддержки производителем и больше не развивались, т.е. обновление
необходимо было в любом случае.
Проблема окончания поддержки коснулась не только системы
подготовки отчётности, но и озера данных на платформе Oracle Big
Data Appliance. К тому моменту а происходило все в 20182019 годах
сотрудники ВТБ уже в полной мере оценили data-driven подход и
потребляли достаточно много данных. Поэтому с точки зрения бизнеса
банка система была критичной. Т.е. перед нами стояла более
глобальная задача масштабов всей инфраструктуры.
Параллельно в объединённом ВТБ началась масштабная цифровая
трансформация, охватившая все уровни IT, начиная от создания новых
ЦОДов и объединения сетей, и заканчивая унификацией
автоматизированных банковских систем и созданием омниканальной
платформы для фронтальных решений. Всё это кардинально меняло
внутренний IT-ландшафт банка.
Поэтому мы задумались не просто об обновлении продукта,
решающего частную задачу сбора отчетности, а об изменении
аналитического ландшафта и подходов по работе с данными.
Логичная идея создание единого аналитического контура, в рамках
которого все данные будут находиться в едином хранилище данных и
доступны для всех пользователей в удобном виде. Это привело нас к
решению о построении платформы данных ВТБ.
Что такое платформа данных? Для себя мы определили её так: это
набор сквозных интегрированных технологических решений
(технологическое ядро), которые являются основой для разработки и
функционирования сервисов по работе с данными банка ВТБ.
Главная часть платформы данных технологическое ядро. Это
системные компоненты, которые переиспользуются на всех уровнях
платформы данных.
Мы выделили 6 компонентов технологического ядра:
-
Управление данными.
-
Управление качеством данных.
-
Управление доступом.
-
Аналитические справочники.
-
Корректировки.
-
ETL Framework.
Концептуальная архитектура платформы данных выглядит следующим
образом:

Ядром платформы данных является СУБД, на которой реализовывается
хранилище данных. Далее расскажу об этом подробнее.
Выбор новой платформы
Поскольку платформа данных содержит персональные данные о
клиентах и банковскую тайну, требования по надёжности и
безопасности были ключевыми. Однако они не лишали нас вариантов
выбора решений, которые могли бы нам подойти, было много.
Мы не просто подбирали систему по набору функций, мы смотрели в
будущее. С точки зрения бизнеса нам выгоднее было искать продукт,
на развитие которого мы сможем оказывать влияние. При этом
разработка собственного инструмента (где все стратегии в наших
руках) всё-таки не входила в наши планы. Это слишком трудозатратный
подход, да и влияние других игроков рынка мы рассматривали как
позитивное. Не только мы должны являться триггером для появления
новых функций. Коллеги по рынку другие клиенты разработчика могли
бы принести в такой продукт интересные идеи. По мере обновления
версий мы получим технологическое развитие.
Мы рассматривали всех крупнейших производителей подобных
решений: Oracle Exadata, Teradata, Huawei. Оценили отечественные
разработки практически все, что есть на рынке. Нам показался
интересным опенсорс, тем более для банка это не первый заход в тему
открытого исходного кода.
В принципе, можно было бы купить железо, скачать открытый код и
собрать собственную платформу данных. Но для нас это означало
серьёзные риски: нужны были компетенции, чтобы доработать всё это
до уровня энтерпрайза. А на момент старта проекта у нас не было
уверенности в успешном завершении подобного мероприятия. Поэтому мы
сформулировали ещё один критерий поставка решения в виде
программно-аппаратного комплекса (ПАК), чтобы совместная работа
железа и программных инструментов была протестирована с учётом
версий. Так мы хеджировали риски, связанные с недостаточной
экспертизой в опенсорсных решениях внутри ВТБ на момент старта
проекта.
При выборе платформы мы учитывали следующие критерии:
-
функциональность
-
качество поддержки
-
отсутствие санкционных рисков
-
возможность гибкого масштабирования
-
надёжность
-
безопасность
-
наличие Road Map развития платформы и возможность на него
влиять
-
стоимость владения совокупные затраты на программно-аппаратный
комплекс на горизонте 10 лет (TCO5).
Если взять последний критерий, то даже с учётом стоимости всех
контуров Arenadata DB и самого проекта миграции мы получали
существенную экономию на фоне Oracle SuperCluster.
В итоге по совокупности факторов мы выбрали Arenadata DB.
Тестирование платформы
Перед тем, как принимать окончательное решение, мы провели серию
технологических испытаний, чтобы проверить систему на
работоспособность и определить параметры сайзинга для целевого
решения.
В итоге нами были проведены следующие проверки.
-
Отключение дисковых устройств на уровне БД для проверки
стабильности работы кластера.
-
Отключение питания одного блока питания на серверах для проверки
стабильности работы кластера.
-
Отключение сетевого подключения для имитации выхода из строя
узла кластера в ходе тестирования отмечается, продолжил ли работать
кластер, и фиксируется степень деградации производительности).
-
Совместимость со средствами резервного копирования
банка:
-
Управление и качество работы системы:
-
Перезагрузка кластера: фиксация успешного выполнения процедуры
перезагрузки.
-
Мониторинг и управление: субъективная балльная оценка от 0 до
5.
-
Генерация тестового отчёта: прогон запроса изсистемы подготовки
отчётности в Arenadata DB для анализа качества результата
генерируемого отчёта результаты выполнения отчёта должны быть
идентичны.
-
Нагрузочное тестирование:
-
Интеграционное тестирование:
Результаты тестирования
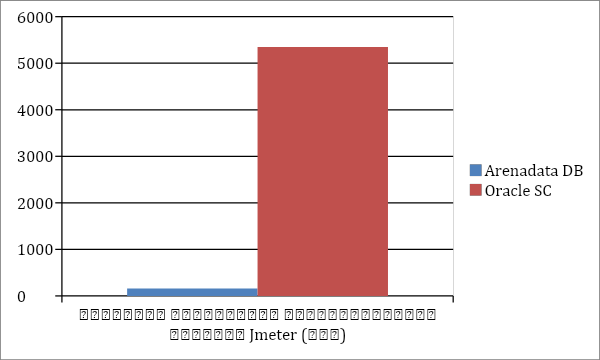
В ходе тестирования кластера Arenadata DB показал высокую
производительность как на синтетических тестах, так и на реальных
нагрузках.
Ниже приведено сравнение скорости выполнения запросов по
сравнению с текущим Oracle Super Cluster T5-8.
Тестирование проводил системный интегратор IBS Platformix.


|
Скорость выполнения синтетического запроса Jmeter
(сек)
|
|
Arenadata DB (сек.)
|
Oracle (сек.)
|
|
160.3
|
1291
|
Кластер показал высокую скорость загрузки данных через
ETL-инструмент Informatica Power Center: 200 Мбит/с.
В ходе тестирования была также осуществлена интеграция с
основными BI-инструментами, используемыми в Банке ВТБ (Oracle BI и
QlikView), и протестирован их функционал.
В QlikView на простейших SQL-запросах протестированы соединение
с БД и выборка данных с последующей загрузкой в модель
BI-инструмента.
Результаты выполнения представлены в таблице ниже.
|
Тест 1
|
Тест 2
|
|
Драйвер
|
ODBC PostgreSQL35W
|
ODBC PostgreSQL35W
|
|
Запрос
|
select * from user.test1
// 3 коротких поля
|
select e.* from dds.accounts e
where
e.entry_dt ='2019-02-03'
-and e.partition_source_system_cd ='00006'
and e.src_deleted is null
|
|
Строк
|
20480000
|
45 920
|
|
Затраченное время
|
0:58
|
2:59
|
|
Скорость загрузки в модель, строк в сек.
|
353103
|
257
|
При выполнении тестов была замечена особенность: получение
первых строк данных из БД происходило с задержкой примерно в 23
секунды. После этого скорость выборки данных из БД и их доставки в
QlikView становилась очень высокой.
Предположительно данная особенность связана c неоптимальной
настройкой коннектора.
Нефункциональное тестирование показало, что кластер не имеет
единой точки отказа и сохраняет свою функциональность при отказе
любого из компонентов.
|
Цель теста
|
Предварительные условия
|
Процедура
|
Результат
|
|
Тестирование отказа диска с данными
|
Отказ диска эмулируется физическим извлечением диска или
логическим отключения дискового уст-ва из работающего сервера.
|
Подключиться к серверу
Провести процедуру unmount для физического диска
Проверить доступность данных
|
Данные доступны
|
|
Тестирование отказа кэширующего диска
|
Отказ диска эмулируется физическим извлечением диска или
логическим отключения дискового устройства из работающего
сервера
|
Подключиться к серверу
Провести процедуру unmount для физического диска
Проверить доступность данных
|
Данные доступны
(Отказ кэширующего диска не приводит к потере данных)
|
|
Тестирование включения кластера после эмуляции аварии
|
Отказ сервера при выполнении SQL запроса к базе данных,
эмулируется отключением электропитания работающего сервера
|
Подключиться к серверу
Выполнить SQL запрос
Выключить 1 ноду
Перезапустить выполнение SQL
|
Данные получены при повторном SQL запросе
|
Благодарю Дениса Степанова и Никиту Клименко, экспертов IBS
Platformix, за предоставленные результаты тестирования.
Сбор отчётности как пилот
Наша цель это миграция на Arenadata DB всех существующих
хранилищ банка ВТБ.
Но в качестве пилота мы запустили перевод систем сбора
обязательной отчётности проект, где обновление было наиболее
критичным.
Arenadata новая для нас платформа, а в перспективе она должна
была стать стратегически важным элементом архитектуры. Поэтому мы
выстроили партнёрство с компанией-производителем максимально
плотно, вплоть до выравнивания планов по развитию. В рамках этого
партнерства часть функционала, который был нам необходим для сбора
обязательной отчетности, реализовали чуть раньше. Доработки
позволили нам развернуть Arenadata на разных ЦОДах, обеспечив таким
образом георезервирование.
Arenadata принципиально не создает под нас отдельное решение, а
немного модифицирует стандартную поставку, так что другие участники
рынка тоже могут пользоваться наработками, реализованными под
одного из клиентов. От такого подхода выигрывают все: и коллеги,
которые могут использовать наши идеи, и мы, поскольку наша
платформа не закуклится внутри инфраструктуры, а будет обновляться
в соответствии с веяниями рынка.
С глобальными сложностями в ходе проекта мы не сталкивались. Да,
было много переговоров, в том числе по вечерам, когда мы
придумывали схемы коммутации серверов и т.п. Но не было нерешаемых
вопросов. Только сложные инженерные задачи.
Сейчас система сбора обязательной отчетности уже частично в
продакшене - мы завершаем тестирование последних форм.
Помимо экономии на стоимости владения, мы получили эффект от
увеличения скорости расчета ряда форм в разы. Это дает нам более
высокую доступность данных - по нашим оценкам в два раза.
Поскольку мы уже видим результаты и детали взаимодействия, около
полугода назад стартовал наш основной проект - миграция на продукты
Arenadata центрального единого хранилища данных и озера данных.
Помимо Arenadata DB, мы используем Arenadata Streaming на базе
Apache Kafka и Arenadata Hadoop на базе Apache Hadoop. В ближайшее
время первые результаты пойдут в продакшен.

Целевая архитектура платформы данных к концу
2022 года
Одновременно с обновлением системы сбора отчетности мы
наращивали экспертизу внутри банка. Как я упоминал выше, на момент
старта мы не были уверены, что сможем запустить такое решение из
чистого опенсорса с нуля. Все это время мы плотно работали с
подрядчиками, которые поставляли нам необходимую экспертизу, а
также через обучение и тренинги развивали экосистему партнеров. Это
наш резерв по разработке, который мы сможем подключить к развитию
проекта в будущем.




 Две чашки
кофе и один QR-код
Две чашки
кофе и один QR-код
 Историю транзакций можно посмотреть на
отдельном экране
Историю транзакций можно посмотреть на
отдельном экране









