

Опаснее всего враг, о котором не подозреваешь.
(Фернандо Рохас)
ИТ-инфраструктуру современной компании можно сравнить со средневековым замком. Высокие стены, глубокий ров и стража у ворот защищают от внешнего врага, а за тем, что происходит внутри крепостных стен, практически никто не следит. Так же и многие компании: они прилагают колоссальные усилия для защиты внешнего периметра, а внутренняя инфраструктура при этом остается обделенной. Внутреннее тестирование на проникновение для большинства заказчиков пока процесс экзотический и не очень понятный. Поэтому мы решили рассказать о нем все (ну, почти все), что вы хотели знать, но боялись спросить.
Внешний враг (страшный хакер в черной толстовке с капюшоном) выглядит пугающе, но огромная часть утечек корпоративной информации происходит по вине инсайдеров. По статистике нашего центра мониторинга Solar JSOC, на внутренние инциденты приходится примерно 43% от общего количества угроз. Одни организации полагаются на средства защиты часто некорректно настроенные, которые можно легко обойти или отключить. Другие вообще не рассматривают инсайдера как угрозу и закрывают глаза на недостатки защиты внутренней инфраструктуры.
Проблемы, которые мы выявляем при анализе внутрянки, кочуют из компании в компанию:
слабые и неизменяемые пароли для сервисных и привилегированных учетных записей;
одинаковые пароли для обычной учетной записи администратора и привилегированной;
одна учетная запись локального администратора на всех рабочих станциях в сети;
ненадежное хранение паролей;
активные учетные записи уволенных сотрудников;
чрезмерные привилегии для сервисных и пользовательских учетных записей;
отсутствие сегментации сети.
Важно: в этом посте речь идет о Windows-сетях с использованием Active Directory.
Кто и что проверяет
Глобально тестирование на проникновение позволяет выявить, насколько потенциальный злоумышленник может навредить ИТ-инфраструктуре конкретной компании. Для этого специалисты по кибербезопасности, проводящие пентест, симулируют действия хакера с применением реальных техник и инструментов, но без вреда для заказчика. Результаты проверки помогают повысить уровень безопасности организации, сократив риски для бизнеса. У такого тестирования есть два направления: внешнее и внутреннее. В первом случае белый хакер должен найти уязвимости, с помощью которых можно проникнуть во внутреннюю сеть (то есть пробить ту самую крепостную стену).
Внутреннее же тестирование на проникновение проверяет, насколько инфраструктура уязвима перед инсайдером или нарушителем, у которого есть доступ в локальную сеть организации. Смогут ли они при желании контролировать ЛВС, беспрепятственно передвигаться по ней и влиять на работу отдельных серверов? Такие работы проводятся во внутренней сети, причем чаще с позиции сотрудника, обладающего минимальными привилегиями. При этом проверять можно (и нужно) даже тех работников, которые имеют только физический доступ к компьютерам (например, уборщики, электрики, охранники, курьеры и пр.).
Пентест не должен выявлять все существующие в компании уязвимости на всех хостах внутренней сети (это можно сделать с помощью сканера уязвимостей или корректной настройкой политик управления уязвимостями). У него совсем другая задача: найти один-два маршрута, по которым может пойти злоумышленник, чтобы успешно атаковать свою жертву. Выполнение работ фокусируется на настройках безопасности и особенностях Windows. Словом, здесь уже не будет производиться, например, сканирование открытых портов и поиск хостов с неустановленными обновлениями.
Как это происходит
Тестирование безопасности внутренней инфраструктуры проходит в несколько этапов:

Вот пример того, как в реальности проходил подобный внутренний пентест в рамках одного из наших проектов:
сначала мы выявили общие файловые ресурсы, на которых располагались веб-приложения;
в одном файле конфигурации обнаружили пароль пользователя SA (Super Admin) к базе данных MS SQL;
с помощью встроенной в MS SQL утилиты sqldumper.exe и процедуры xp_cmdshell получили дамп процесса LSASS, через подключение к СУБД:
из процесса извлекли пароль пользователя с привилегиями доменного администратора.

Так как внутреннее тестирование на проникновение рассматривает только внутреннюю (что очевидно) инфраструктуру организации, совершенно не важно, каким образом злоумышленник получил первоначальный доступ в сеть важно, как он воспользовался этим доступом. Поэтому в финальном отчете, составленном по итогам пентеста, описываются не обнаруженные уязвимости, а история того, как специалист продвигался по сети, с какими препятствиями и трудностями он столкнулся, как их обошел и каким образом выполнил поставленную задачу. Специалист может обнаружить несколько недостатков, но для достижения цели будет выбран один самый оптимальный или интересный. При этом все замеченные по дороге уязвимости также попадут в отчет. В результате заказчик получит рекомендации по исправлению недочетов и повышению уровня безопасности внутренней инфраструктуры.
По сути внутренний пентест продолжает внешний, отвечая на вопрос: Что произойдет после того, как киберпреступник попал в сеть?. Для сравнения в процессе тестирования на проникновение внешнего периметра обычно используется следующая методология:

Кто заходит в инфраструктуру
Итак, каким образом злоумышленник попал в сеть не важно, поэтому на начальном этапе планирования работ по внутреннему пентесту могут рассматриваться модели инсайдера или внешнего нарушителя.
1) Модель инсайдера. Инсайдер это мотивированный внутренний злоумышленник, у которого есть легитимный доступ к инфраструктуре организации, ограниченный только должностными обязанностями. Например, реальный сотрудник, который решил навредить своей компании. Также в роле инсайдеров могут выступать сотрудники вспомогательных служб (охранники, уборщики, электрики и др.), у них есть легитимный доступ в офис, но отсутствуют права доступа к инфраструктуре.
2) Модель внешнего нарушителя. Модель не фокусируется на том, каким образом был получен доступ (уязвимость в ПО периметра, утечка учетных данных, социальная инженерия или что-то другое) во внутреннюю сеть организации. За начальную точку принимается тот факт, что чужак уже внутри.
После составления модели угрозы моделируется и сама ситуация, при которой исполнитель получит доступ к инфраструктуре:
физический доступ с предоставлением рабочего места и учетных данных пользователя;
физический доступ с предоставлением доступа в сеть без учетных данных. Доступ в сеть может быть как проводной, так и беспроводной (Wi-Fi);
удаленный доступ к рабочему месту или сервису удаленных рабочих столов. Это самый распространенный вариант: в данном случае моделируется или инсайдер, или злоумышленник, получивший доступ через утечку учетных данных либо перебор паролей;
запуск вредоносного документа, эмуляция фишинговой атаки. Документ запускается с целью установки канала связи с командным центром (Command & Control), откуда будет проводиться пентест. Этот метод относительно новый для тестирования безопасности внутренней инфраструктуры, но наиболее реалистичный с точки зрения действий злоумышленника.
При этом пентест это не бесцельное блуждание по чужой инфраструктуре. У белого хакера всегда есть цель, поставленная заказчиком. Самым распространённым сценарием для внутреннего тестирования на проникновение является получение привилегий доменного администратора. Хотя в реальности злоумышленники редко стремятся получить такие привилегии, так как это может привлечь к ним ненужное внимание. Поэтому в большинстве случаев привилегии доменного администратора будут скорее не целью, а средством ее достижения. А целью может стать, например, захват корпоративной сети, получение доступа к рабочей станции и серверу или к приложению и базе данных.
Кому все это нужно
А стоит ли вообще заказчику пускать пентестеров в свою корпоративную сеть? Однозначно, стоит. Именно здесь находятся самые критичные данные и главные секреты компании. Чтобы защитить ЛВС, необходимо знать все ее закоулки и недостатки. И внутреннее тестирование на проникновение может в этом помочь. Оно позволяет увидеть слабые места в инфраструктуре или проверить настроенные контроли безопасности и улучшить их. Кроме того, внутренний пентест это более доступная альтернатива Red Team. Ну, если есть задача продемонстрировать руководству, что выделяемых средств недостаточно для обеспечения безопасности внутренней инфраструктуры, внутренний пентест позволяет подкрепить этот тезис фактами.
Автор: Дмитрий Неверов, эксперт по анализу защищенности, Ростелеком-Солар

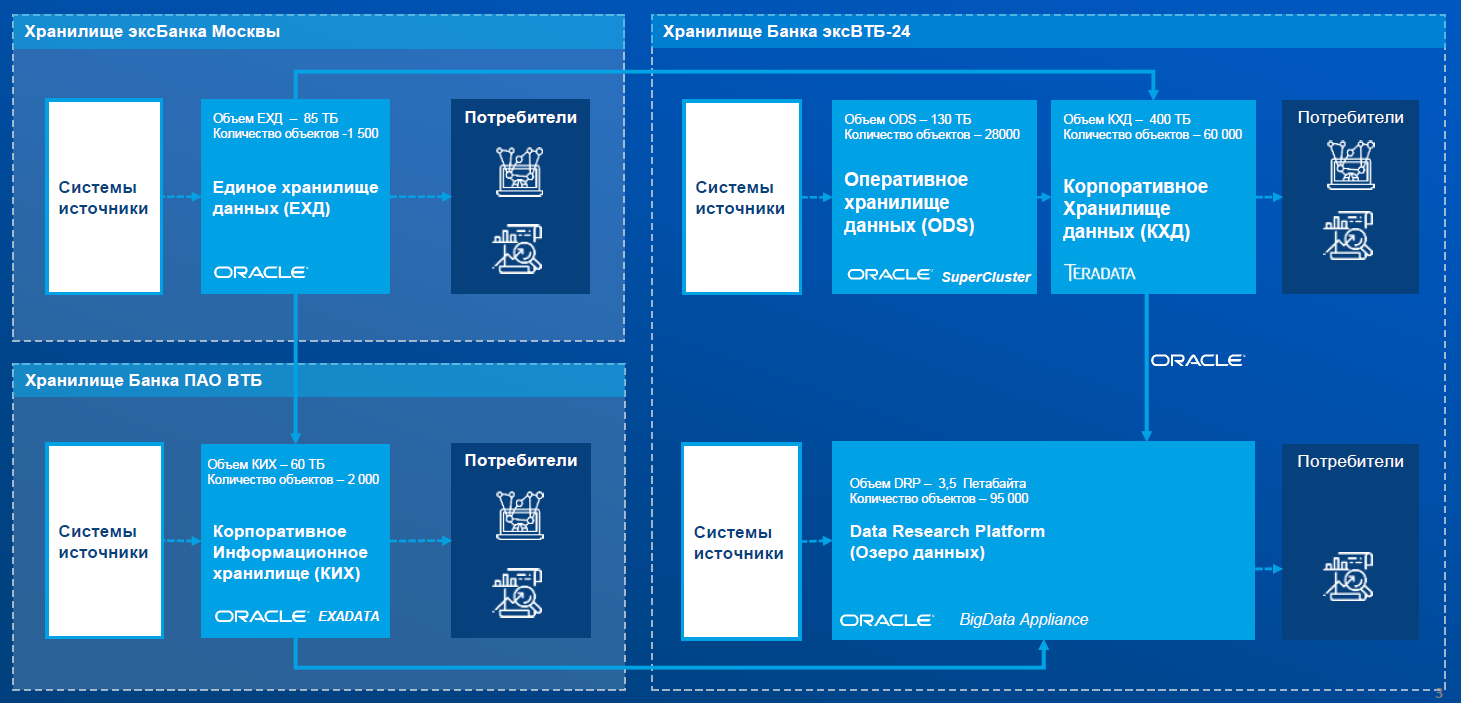



 Целевая архитектура платформы данных к концу
2022 года
Целевая архитектура платформы данных к концу
2022 года




















































 Своевременная ставка корпораций Apple и
Google на развитие своих магазинов во многом определила современное
состояние рынка мобильных ОС
Своевременная ставка корпораций Apple и
Google на развитие своих магазинов во многом определила современное
состояние рынка мобильных ОС
 ВВП в долларах на душу населения по годам
ВВП в долларах на душу населения по годам
























 На фотографии изображены студентки
кабульского политехнического института - представительницы типичной
кабульской молодежи 70-х
На фотографии изображены студентки
кабульского политехнического института - представительницы типичной
кабульской молодежи 70-х
 Афганская сторона впервые принимает
генерального секретаря товарища Хрущева Н.С. 1955 год.
Афганская сторона впервые принимает
генерального секретаря товарища Хрущева Н.С. 1955 год.
 На фотографии красуються бортпроводницы
компании Ariana Afganistan Airlines. Кабул начало 70-х
На фотографии красуються бортпроводницы
компании Ariana Afganistan Airlines. Кабул начало 70-х

 Советский воин должен стойко переносить
все тяготы и лишения военной службы
Советский воин должен стойко переносить
все тяготы и лишения военной службы
 Более чем на 9 лет мировое сообщество
закрыло глаза на все бесчинства Талибана в огромном 30 миллионном
государстве
Более чем на 9 лет мировое сообщество
закрыло глаза на все бесчинства Талибана в огромном 30 миллионном
государстве
 Как следствие сложного рельефа и
близости этнических групп населяющих регион, Афгано-Пакистанская
граница и сейчас остается довольно условным фактором
Как следствие сложного рельефа и
близости этнических групп населяющих регион, Афгано-Пакистанская
граница и сейчас остается довольно условным фактором
 Централью часть Афганистана составляют
неприступные горы Гиндукуш. Высота наивысшей горы Ношак составляет
7492 м
Централью часть Афганистана составляют
неприступные горы Гиндукуш. Высота наивысшей горы Ношак составляет
7492 м
 Не смотря на мусульманские традиции и
крепко засевший в наших головах стереотип афганской женщины -
наглухо замотанной в бурку, требование полностью скрывать лицо
девушкам старше 8 лет существовало в Афганистане только на
протяжении короткого периода узурпации талибами власти с 1992 по
2001 год
Не смотря на мусульманские традиции и
крепко засевший в наших головах стереотип афганской женщины -
наглухо замотанной в бурку, требование полностью скрывать лицо
девушкам старше 8 лет существовало в Афганистане только на
протяжении короткого периода узурпации талибами власти с 1992 по
2001 год
 Протяженность национальной ИТ-кольцевой
составляет более 2500 км. В 2007 году она объединила наиболее
населенные города Афганистана и позволила населению страны впервые
получить доступный интернет
Протяженность национальной ИТ-кольцевой
составляет более 2500 км. В 2007 году она объединила наиболее
населенные города Афганистана и позволила населению страны впервые
получить доступный интернет
 Помесячная цена на не лимитированные
пакеты проводного интернета с гарантированной скоростью в 1Мбит/с
для г.Кабул
Помесячная цена на не лимитированные
пакеты проводного интернета с гарантированной скоростью в 1Мбит/с
для г.Кабул


 Количество в тоннах производимого в
Афганистане опиума по годам
Количество в тоннах производимого в
Афганистане опиума по годам
 Пригород Кабула
Пригород Кабула
 Особенностью Афганистана является высокая
концентрация населения в городах. Так в городской агломерации
Кабула проживает около 4.5 миллиона людей. Данная специфика особо
способствует внедрению интернета в стране
Особенностью Афганистана является высокая
концентрация населения в городах. Так в городской агломерации
Кабула проживает около 4.5 миллиона людей. Данная специфика особо
способствует внедрению интернета в стране

 Фотография: Oscar Schnell. Источник: Unsplash.com
Фотография: Oscar Schnell. Источник: Unsplash.com
 Фотография: Nadine Shaabana. Источник: Unsplash.com
Фотография: Nadine Shaabana. Источник: Unsplash.com