Webix UI
Эта статья предназначена для тех, кто ценит свое время и не
желает тратить многие месяцы на дотошное изучение нативных
технологий web разработки. Знать и разбираться в них безусловно
полезно, но в современном мире технологии развиваются настолько
стремительно, что уследить за всеми тонкостями - задача не из
легких. Чтобы не чахнуть над талмудами скучнейших документаций,
которые изменятся уже завтра, можно использовать готовые
решения.
Одно из лучших решений предлагает нам команда Webix. Их библиотеку UI
компонентов мы и рассмотрим в этой статье.
Для наглядности создадим собственное приложение для поиска и
бронирования авиабилетов. Не за горами сезон летних отпусков, так
что такой выбор как никогда актуален.
С кодом готового приложения можно ознакомиться тут.
Немного о Webix и его возможностях
Webix UI это JavaScript
библиотека, которая позволяет создавать отзывчивый дизайн и
обеспечивает высокую производительность приложения. Диапазон
возможностей представлен UI компонентами различной сложности, от
обычной кнопки, до таких комплексных решений, как Report Manager, с помощью
которого можно создавать и экспортировать отчеты данных. Помимо
самих компонентов, библиотека предоставляет много дополнительных
возможностей для работы с ними. Например, механизм обработки
событий, методы работы с данными, взаимодействие с сервером, темы
для стилизации и многое другое. Обо всем этом и не только можно
узнать в документации. А
сейчас самое время перейти к практической части.
Источник UI магии
Магия не происходит сама по себе. Для того, чтобы ее
использовать, нужно знать заклинания и обладать секретом ее силы.
Пришло время приподнять завесу таинственности и сделать эти знания
доступными не только для узкого круга посвященных.
Итак, для того, чтобы начать использовать библиотеку, нужно
сперва получить необходимые файлы (они же источники
webix-магии). Для этого переходим на страницу загрузки, вводим
необходимые данные и получаем ссылку на скачивание заветного
zip-файла. Скачиваем и распаковываем его. Внутри находятся файлы
license.txt, readme.txt и whatsnew.txt,
которые могут заинтересовать тех, кто любит глубоко погрузиться в
изучение вопроса. Кроме этого, в папке samples можно посмотреть
примеры того, какие полезные вещи можно сотворить при помощи Webix
UI.
Больше всего нас интересует содержимое папки codebase, а именно,
два сакральных файла: webix.js и webix.css. Для
того, чтобы Webix-магия начала действовать, нужно включить их в
index.html файл будущего проекта:
<!DOCTYPE html><html> <head> <title>Webix Booking</title> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="codebase/webix.css"> <script type="text/javascript" src="codebase/webix.js"></script> </head> <body><script type="text/javascript">...</script> </body></html>
Внутри кода мы добавим теги
<script>...</script>,
где и будем собирать наше приложение.
Впрочем, архив с библиотекой скачивать не обязательно.
Необходимые файлы доступны также через CDN. Подключить их можно
следующим образом:
<link rel="stylesheet" type="text/css" href="http://personeltest.ru/away/cdn.webix.com/edge/webix.css"><script type="text/javascript" src="http://personeltest.ru/away/cdn.webix.com/edge/webix.js"></script>
Инициализация
Теперь давайте перейдем непосредственно к работе с Webix.
Вся Webix-магия происходит внутри конструктора
webix.ui(). Нам нужно убедиться в том,
что код начнет выполняться после полной загрузки HTML страницы. Для
этого обернем его в
webix.ready(function(){}). Выглядит это
следующим образом:
webix.ready(function(){webix.ui({ /*код приложения*/});});
После создания index.html файла и подключения
необходимых инструментов, самое время перейти к непосредственной
разработке нашего Booking приложения. Начнем с интерфейса.
Создаем приложение Booking
Интерфейс нашего приложение будет состоять из следующих
частей:
-
Тулбар
-
Форма поиска рейсов
-
Таблица рейсов
-
Форма заказа.
Каждую из частей мы будем разрабатывать и хранить в отдельных
файлах, а соберем их в файле index.html. Предлагаю
детально ознакомиться с тем, как это реализуется на практике. А
начнем мы с построения лейаутов, которые определяют способ
расположения элементов на странице.
Лейаут
Чтобы наполнить страницу содержимым, нужно описать необходимые
элементы в формате JSON. Давайте создадим каркас нашего приложения
и постепенно будем добавлять туда новые компоненты.
Для сознания лейаута предусмотрены такие сущности, как
rows и cols, с
помощью которых можно разбить страницу на строки и столбцы,
отделенные между собой границами. Каждое из свойств содержит
массив, внутрь которого можно поместить другие компоненты.
Сначала разделим наш лейаут на 2 одинаковых ряда. Для этого
воспользуемся свойством rows:
webix.ui({ rows: [ { template:"Row One" }, { template:"Row Two" } ]});
Теперь лейаут будет выглядеть следующим образом:

В этом примере с помощью выражения template:"Row
One" мы создали простой контейнер, в который можно
поместить любой HTML-контент.
В верхний ряд этого лейаута мы поместим Тулбар. В нижнем будут
находиться 2 сменяемых модуля:
-
Модуль поиска рейсов
-
Модуль заказа рейсов.
Модуль поиска рейсов нужно разделить на 2 столбца. В левом мы
разместим форму поиска, а в правом таблицу данных. Для этого
воспользуемся свойством cols:
webix.ui({ rows: [ { template:"Toolbar", height:50}, { cols:[ { template:"Search Form" }, { template:"Data Table" } ] } ]});
Теперь лейаут будет иметь следующий вид:

Комбинируя таким образом вложенные строки и столбцы, можно
добиться необходимого результата. По умолчанию контейнеры заполняют
все доступное пространство. Создавая два контейнера, мы получим 2
одинаковых прямоугольных области. Для того, чтобы задать нужные
размеры элементов, можно использовать знакомые всем по CSS свойства
width и
height.
Теперь перейдем к модулю заказа рейсов и также разделим его на 2
столбца. В левом мы разместим форму заказа, а правый столбец
оставим пустым. А почему же пустым, спросите вы? Ответ простой:
если этого не сделать, форма растянется на весь экран, а это не
очень эстетично. Пустой компонент, он же spacer,
помогает выравнивать компоненты в интерфейсе. После этого мы можем
задать необходимый размер нашей формы, а лишнее пространство будет
заполнено этим отсутствующим компонентом, если можно так
выразиться.
Здесь мы снова воспользуемся уже знакомым атрибутом
cols. Стоит напомнить, что компоненты
внутри cols и rows по умолчанию разделены тонкой
серой линией. Такой разделитель между формой и спейсером нам ни к
чему. Webix позволяет управлять им с помощью свойства type:
webix.ui({ rows: [ { template:"Toolbar", height:50 }, { type:"clean", //убираем линию-разделитель cols:[ { template:"Order Form" }, {} ] } ]});
Результат будет следующим:

Мы создали отдельные лейауты для модулей поиска и заказа рейсов.
Теперь нужно сделать их сменяемыми. Как вы уже догадались, Webix
предусматривает и такую возможность. Реализуется она с помощью
multiview
компонента.
Для этого нужно поместить необходимые модули в массив свойства
cells и присвоить им соответствующие
id. Стоит упомянуть, что при
первоначальной загрузке будет отображаться модуль поиска рейсов,
который задан первым элементом массива, но о том, как сменяются
модули, мы поговорим чуть позже.
А сейчас наш код будет выглядеть следующим образом:
webix.ui({ rows:[ { template:"Toolbar", height:50 }, { cells:[ { id:"flight_search", cols:[ {template:"Search Form"}, {template:"Data Table"}, ] }, { id:"flight_booking", type:"clean", cols:[ {template:"Order Form"}, {}, ] } ] } ]});
Мы уже знаем, как работать с лейаутами. Теперь пришло время
приступить к разработке непосредственно компонентов интерфейса
нашего приложения.
Тулбар
Тулбар важная часть любого приложения. Зачастую там
располагаются инструменты управления и прочие ништяки. В нашем
случае тулбар будет иметь динамически сменяемый лейбл.
В файле toolbar.js создаем компонент с помощью
следующей строки:
const toolbar = { view:"toolbar" };
Нужно уточнить, что каждый значимый компонент мы сохраняем в
переменной, чтобы потом использовать его для сборки в лейауте.
Как мы видим, тип создаваемого компонента определяется значением
свойства view. В нашем случае это
toolbar.Давайте
стилизуем компонент и добавим лейбл с названием:
{ view:"toolbar" css:"webix_dark", //стилизация cols:[ { id:"label", //указываем id для обращения view:"label", label:"Flight Search", //название } ]}
Выше мы упоминали, что вставлять компоненты друг в друга
необходимо при помощи свойств rows и cols.
Поэтому компонент label мы
включаем в массив свойства cols компонента
toolbar.
С помощью свойства id будет происходит
обращение к элементу. Он должен быть уникальным. В нашем случае это
нужно для динамической смены лейбла, но к этому мы еще
вернемся.
Вот такими нехитрыми маневрами мы создали тулбар нашего
приложения.Чтобы использовать компонент в лейауте, нужно сначала
подключить файл toolbar.js в index.html и
включить переменную в массив свойства rows вместо
{template:Toolbar}:
webix.ui({rows: [ toolbar, { cells:[ ... ] }]});
На странице браузера мы увидим лейаут с интерфейсом тулбара:

Выглядит уже неплохо. Теперь настало время перейти к разработке
модуля поиска рейсов. Он состоит из 2 частей:
-
Форма поиска рейсов
-
Таблица рейсов.
Давайте рассмотрим их детально.
Форма поиска рейсов
Форма поиска нам нужна для фильтрации данных о рейсах. Давайте
разбираться, по каким параметрам должен происходить поиск и как это
реализовать на практике.
Классическую форму можно создать при помощи элемента
<form>, а внутри определить необходимые контролы.
При этом нужно оперировать большим количеством тегов и атрибутов.
Для обработки же данных и вовсе требуется чуть ли не докторская
степень.
Webix предлагает сделать это гораздо проще. Давайте с этим
разбираться.
Создадим нашу форму в файле search_form.js с помощью
компонента form:
const search_form = { view:form };
Постепенно мы будем задавать элементы, которые нужны нам для
поиска. Для этого воспользуемся свойством
elements:
{ view:form, ... elements:[ { /*элемент формы*/ }, { /*элемент формы*/ }, ... ] ...}
Как вы видите, определять элементы формы необходимо внутри
массива elements. Напомню, что каждый компонент библиотеки
описывается с помощью json объекта. Давайте же узнаем, что нам
могут предложить разработчики Webix для работы с формами.
Форма Webix имеет множество преимуществ. Она позволяет
устанавливать и считывать значения всех входящих в нее полей сразу,
а не по одному. Для этого нужно указать свойство
name в конфигурации каждого поля. Также
вы можете связывать ее с другими компонентами или сохранять данные
непосредственно на сервер. Подробнее о работе с формами можно
узнать здесь.
А сейчас нужно определиться с элементами, которые мы будем
реализовывать. Чтобы выбрать пункты отправления и назначения,
необходимо установить селекторы выбора городов. Также мы будем
искать рейсы по дате отправления и возвращения. Контрол даты
возвращения нужно спрятать и отображать его при необходимости.
Реализуем это с помощью радиокнопок One Way и Return. При поиске
нужно учитывать количество необходимых билетов. Для этого установим
специальный счетчик. Ну и конечно, как же без кнопок управления
формой Reset и Search. В итоге наша форма будет иметь следующий
вид:

Теперь можно приступить к реализации задуманного.
Радиокнопки
В самом начале формы нужно определить радиокнопки, с помощью
которых мы будем отображать и прятать контрол выбора даты
возвращения. Делается это с помощью элемента radio:
{ view:"radio", label:"Trip", name:"trip_type", value:1, options:[ { id:1, value:"One-Way" }, { id:2, value:"Return" } ]}
Значения радиокнопок задаем через свойство
options. Помимо этого, указываем название
компонента через свойство label, а имя,
по которому будем получать значение, через
name. По умолчанию мы будем искать полеты
только в одну сторону, поэтому устанавливаем для
value значение именно этой опции.
Селекторы выбора городов
Чтобы указать пункты отправления и назначения, нам понадобятся
специальные селекторы. Создадим их с помощью элемента combo:
{ view:"combo", id:"from", clear:"replace", ... placeholder:"Select departure point", options:cities_data}
Иногда пользователю необходимо подсказать, что нужно делать с
тем или иным контролом. И тут на помощь нам приходит свойство
placeholder. Мы указываем нужные
действия, а приложение отобразит их в поле необходимого элемента.
Когда пользователь ввел или выбрал нужные данные, но потом вдруг
передумал, а такое случается довольно часто, мы предоставим ему
возможность очистить поле одним кликом. Для этого нужно задать
свойство clear в значении
replace. Теперь, когда поле будет заполнено, в правой его
части появится иконка, при клике по которой введенные ранее данные
исчезнут (поле будет очищено).
При клике по селектору должен появиться выпадающий список опций
с названиями городов. Давайте это реализуем. Данные для списка
опций можно задавать через свойство options
. Есть несколько способов загрузить данные в
компоненты Webix. Можно задать их в виде массива напрямую, или же
хранить в отдельном файле и просто указать необходимый URL, а
компонент сам загрузит их.
Но дело в том, что эти же данные нам нужны для нескольких
компонентов, а загружать их для каждого по отдельности будет
несколько затратно. Webix решает эту проблему с помощью такой
сущности, как DataCollection.
Внутри этого компонента необходимо всего лишь указать URL, по
которому будут загружаться данные. Информация загрузится один раз и
будет доступна для многоразового использования. В нашем случае
объект с данными хранится в файле ./data/cities.json.
Давайте создадим коллекцию и для удобства сохраним ее в
переменную:
const cities_data = new webix.DataCollection({ url:"./data/cities.json"});
Теперь данные доступны для использования в наших селекторах и не
только.
Выше мы описали селектор выбора точки отправления. Второй
селектор, который определяет пункт назначения, имеет незначительные
отличия, на которых мы не будем останавливаться.
Селекторы выбора дат
Расписание - одна из важнейших составляющих современной жизни.
При поиске рейсов обязательно нужно это учитывать. Давайте
предоставим пользователю возможность указывать желаемое время
вылета при поиске необходимого рейса. Сделаем мы это с помощью
такого элемента, как datepicker:
{ view:"datepicker", name:"departure_date", ... format:"%d %M %Y"}
При клике на селектор появится компактный календарь, в котором
можно выбрать необходимую дату. Более того, у нас есть возможность
задать необходимый формат, в котором выбранная дата будет
отображаться в поле селектора. Реализуется это через свойство
format.
Зададим такой же селектор для выбора даты обратного рейса, но
изначально спрячем его при помощи свойства
hidden. Именно этот селекор мы будем
отображать при выборе радиокнопки Return, но об этом позже.
Счетчик количества билетов
Представим себе ситуацию, что наш потенциальный пользователь
летит в долгожданный отпуск не один, а со всей семьей или компанией
друзей. В таком случае ему понадобится не один билет, а некое энное
количество. Давайте позволим ему устанавливать необходимое число
билетов. Для этого предусмотрен специальный элемент counter.
Использовать его очень удобно. С правой и левой стороны находятся
иконки со знаками плюс и минус, с помощью которых и происходит
увеличение или уменьшение значения. Нужно также установить
минимальное значение через свойство min,
чтобы пользователь не смог установить меньше 1 билета
(согласитесь, это выглядело бы абсурдно). Код элемента
будет выглядеть следующим образом:
{ view:"counter", name:"tickets", label:"Tickets", min:1 }
Кнопки поиска и сброса формы
Пользователь определился с параметрами поиска и заполнил
необходимые поля. Теперь нужно создать кнопки, которые позволят
запустить поиск нужных рейсов по указанным параметрам или очистить
форму.
Для этого мы предусмотрим соответствующие кнопки
Search и Reset. Определяем их с
помощью элемента button.
Название кнопок указываем через value, а
стилизацию добавляем через свойство css.
Здесь нужно уточнить, что библиотека предусматривает встроенную
стилизацию кнопок. Мы будем использовать класс
"webix_primary" для стилизации кнопки Search. Подробнее о
стилизации кнопок можно узнать здесь.
Для удобства мы разместим наши кнопки в виде столбцов:
{ cols:[ { view:"button", value:"Reset" }, { view:"button", value:"Search", css:"webix_primary" } ]}
Интерфейс формы поиска мы создали. Теперь давайте интегрируем
его в наш лейаут - вы еще помните о нём? Для этого, как и в примере
с тулбаром, нужно включить файл search_form.js в
index.html. Интерфейс формы хранится в переменной
search_form, которую мы и пропишем в лейауте:
[ toolbar, { cells:[ { id:"flight_search", cols:[ search_form, { template:"Data Table" } ] }, ... ] },]
Интерфейс приложения будет выглядеть следующим образом:

Таблица рейсов
Пользователь ввел данные, нажал кнопку Search и ожидает увидеть
результат. А результат будет отображаться в специальной таблице,
созданием которой мы сейчас и займемся.
Возможности Webix таблицы сложно переоценить. Ее функционал
начинается с отображения, фильтрации и сортировки данных, а
заканчивается экспортом в PDF или Excel. Можно написать целую книгу
о ее возможностях, продать и заработать баснословные деньги, но в
данный момент нас больше интересует то, как сконфигурировать
таблицу именно под наши нужды.
В файле datatable.js создаем таблицу рейсов с помощью
компонента datatable:
const flight_table = { view:"datatable", url:flights_data};
Таблицу нужно заполнить данными о расписании рейсов. В нашем
случае они хранятся в файле ./data/flights_data.json. Одно из
преимуществ работы с таблицами Webix заключается в том, что можно
просто указать путь к файлу или скрипту, а компонент сам сделает
запрос, загрузит данные и отобразит их в соответствии с
настройками. Проще только вообще ничего не делать.
Путь к данным нужно указывать через свойство
url. Для удобства мы сохраним путь в
переменную flights_data и присвоим ее нашему свойству.
Данные мы загрузили, теперь нужно их красиво отобразить. Для
ооочень ленивых прогеров, Webix предусмотрел такое свойство как
autoConfig. Если
задать для него значение true, то данные автоматически
распределятся в столбцы в соответствии с имеющимися полями.
Но мы еще не настолько разленились, чтобы прибегать к таким
хитростям. Тем более, настройка столбцов вручную сулит нам
множество увлекательных и полезных возможностей. Давайте взглянем
на них более пристально.
Конфигурация столбцов происходит в массиве свойства
columns:
columns:[ { /*конфигурации столбца*/ }, { /*конфигурации столбца*/ }, ...]
Чтобы данные из файла попали в нужный нам столбец, необходимо
указать id, значение которого должно
совпадать с полем, в котором хранятся соответствующие данные в
файле.
У столбца должно быть название, или по-простому шапка. Шапку мы
задаем при помощи свойства header.
Нередко бывают ситуации, когда данные приходят в одном виде, а
отобразить их нужно в другом. Было бы нелепо предположить, что
разработчики Webix не учли такой вероятности и не решили эту
проблему заранее. Поэтому нам доступно свойство
format.
Если мы уже коснулись вопроса изменения данных, то нужно
остановиться на этом более детально. Вопрос актуален для нас и тем,
что для некоторых столбцов мы будем применять форматирование. Речь
идет о датах и названиях городов.
Давайте рассмотрим пример с датами.
Дело в том, что их значения хранятся и загружаются в виде строк
типа "2021-03-26". Как вам
должно быть известно, оперировать строчными датами не самое
приятное занятие (для некоторых даже болезненное). Исходя
из этого, можно сразу при загрузке перевести их в JS
Date объекты. С помощью свойства
scheme мы можем переопределить все строки
указанного поля (данные которого попадут в столбец с таким же
id) в соответствующие объекты Date
перед их загрузкой в таблицу:
scheme:{ $init:function(obj){ obj.date = webix.Date.strToDate("%Y-%m-%d")(obj.date); }}
Теперь значения дат попадают в столбец Date в виде объектов, а
не строк. Так будет гораздо удобнее фильтровать рейсы при поиске
билетов. Но на этом все не заканчивается. Нужно настроить их
отображение непосредственно в ячейках столбца. Для этого в
конфигурации столбца мы прописываем уже упомянутое свойство
format в значении
webix.i18n.longDateFormatStr. Теперь
полученный объект Date преобразуется в
заданное свойством format значение и отображается как
26 March 2021. Вот такая вот
магия.
Столбцы, которые отображают названия городов, также заслуживают
особого внимания. Дело в том, что данные о пунктах отправления и
назначения хранятся и приходят в виде чисел. Зачем такие сложности
спросите вы? Ответ простой. Сами названия городов хранятся в
отдельной серверной таблице как id - value, а в данных о рейсах
вместо названий хранятся только id городов. Чтобы получить название
города по его id, нам нужно воспользоваться свойством
collection.
Хочу напомнить, что при разработке селекторов выбора
городов, мы создали коллекцию данных и сохранили ее в
переменной cities_data. Вся
прелесть работы с коллекциями заключается в том, что данные
загружаются 1 раз и доступны для использования в неограниченном
количестве.
Так вот, свойство collection
отправляет запрос в коллекцию данных
cities_data и получает соответствующее
название города по его id, который
соответствует числовому значению ячейки столбца. Здесь и
добавить-то больше нечего. Такие мелочи делают процесс разработки
приятным развлечением.
Но развлечения мы оставим на вечер пятницы. Сейчас нужно
представить, что потенциальный пользователь ввел данные в форму
поиска, нажал кнопку Search и нашел необходимый рейс в таблице
(пока нужно только представить, так как реализацией интерактива
мы займемся во второй части). Какие дальнейшие действия?
Безусловно, нужно как можно быстрее помочь ему забронировать рейс.
Как это сделать?
Для удобства бронирования в конце каждого ряда будет находиться
кнопка, при клике по которой пользователь будет переходить к форме
заказа. Но ни слова больше. Весь интерактив будет во второй части
статьи, где мы вдохнем жизнь в статические интерфейсы.
Если вас заинтересовали возможности таблицы и непосредственно
конфигурации столбцов, дополнительную информацию можно получить
здесь.
А мы же продолжаем настраивать таблицу.
Наш пользователь нашел несколько рейсов (10, 100 или
больше), которые соответствуют его запросам. Нужно помочь ему
найти нужный рейс непосредственно в таблице. Давайте добавим строку
поиска и разместим ее над таблицей, чтобы потенциальный
пользователь нашел наконец-то свой рейс и с довольным лицом
рассказывал своим друзьям и знакомым, какой крутой у нас
сервис.
Для этого мы воспользуемся компонентом search:
const search_bar = { view:"search" };
Это текстовое поле с красивой иконкой поиск.
Когда все уже готово, остается интегрировать компоненты в наш
лейаут. И выглядит это следующим образом:
[ toolbar, { cells:[ { id:"flight_search", cols:[ search_form, { rows:{ search_bar, flight_table } } ] }, ... ] },]
Уже всё по-взрослому. Результат в браузере будет таким:

Форма заказа
Пользователь определился с рейсом и готов сделать заказ. Давайте
поможем ему сделать это. Пришло время заняться формой заказа. Она
будет отображаться вместо модуля поиска рейсов при клике по кнопке
Book в таблице. Форма будет иметь следующий вид:

Для того, чтобы реализовать весь этот функционал, воспользуемся
уже знакомым нам компонентом form и пропишем
следующее:
const order_form = { view:"form", elements:[ ... ]};
Теперь давайте опишем нужные нам элементы.
Поля ввода
Для заказа рейса нам нужно получить от пользователя его личные
данные. Чтобы это сделать, мы создадим соответствующие поля
ввода.
Давайте воспользуемся элементом text
и его преимуществами:
elements:[ { view:"text", name:"first_name", , invalidMessage:"First Name can not be empty" }, { view:"text", name:"last_name", , invalidMessage:"Last Name can not be empty" }, { view:"text", name:"email", , invalidMessage:"Incorrect email address" }, ...]
В отличие от формы поиска здесь нам нужно добавим валидацию.
Личные данные вещь серьезная, и пока пользователь не введет их
правильно, он не сможет сделать заказ. Давайте предусмотрим такой
сценарий, где пользователь не ввел личные данные или ввел их
неправильно и отправил на обработку. Что же должно произойти между
делом? Правильно, данные должны проверяться.
Webix предусматривает такое развитие событий и предоставляет нам
готовое решение в виде свойства rules
и набора условий для проверки введенных данных. Можно, конечно, и
самому написать эти правила, создать несколько функций, прочитать
пару книг по регулярным выражениям, сходить на курсы по их
применению и вернуться обратно к встроенным правилам, потому что
они реально удобны. Все, что нужно сделать, это присвоить правила
соответствующим именам (свойствам name) полей формы в
массиве rules:
{ elements:[ ], rules:{ first_name:webix.rules.isNotEmpty, //поле не должно быть пустым last_name:webix.rules.isNotEmpty, email:webix.rules.isEmail //значение должно быть в формате email }}
Если значение поля соответствует установленному правилу, форма
разрешит дальнейшие действия. В противном случае, поля подсветятся
красным. Но пользователю красное поле ни о чем конкретном не
говорит. Он поймет, что сделал что то неправильное, но не поймет,
что именно мы от него хотим.
Для этого у Webix элементов есть хорошее решение в виде свойства
invalidMessage. Для каждого поля можно
задать сообщение, которое появится в случае неправильных
данных:
{ ..., invalidMessage:"First Name can not be empty", ... }
Закрадывается мысль, что у Webix есть готовые решения на все
случаи жизни. Но нужно помнить, что это всего лишь UI библиотека, а
настоящая валидация по-хорошему должна происходить на сервере.
Счетчик
В форме поиска наш пользователь установил нужное количество
билетов и нажал кнопку Book напротив необходимого рейса. Приложение
отобразило форму заказа, где он может подтвердить его. Но у нашего
пользователя вдруг возникло желание заказать не 2 билета (как
он указал при поиске), а три. Давайте дадим ему возможность
изменять количество билетов прямо в форме заказа.
Для этого используем уже знакомый нам элемент
counter. По сути, он такой же, как и в предыдущей
форме. Его первоначальное значение будет зависеть от значения
счетчика формы поиска и количества свободных мест на выбранном
рейсе. С его помощью пользователь сможет изменять количество
необходимых билетов, не возвращаясь назад к поиску:
{ view:"counter", id:"tickets_counter", name:"tickets", label:"Tickets", min:1 }
Чекбоксы
Каждый из нас хоть раз пользовался услугами авиакомпаний и
знает, что за дополнительный багаж, который не влез в разрешенную
ручную кладь, нужно доплатить. Помимо этого, если перелет
планируется длинным, мы предоставим возможность включить стоимость
еды в цену билета. Давайте посмотрим, как это реализовать.
Для этого мы создадим 2 чекбокса Checked-in Baggage и Food и
будем их использовать для того, чтобы повышать цену за билет, если
пользователь выбрал эти дополнительные плюшки. Чекбокс реализуется
с помощью элемента checkbox:
[ { view:"checkbox", name:"baggage", label:"Checked-in Baggage", checkValue:15 }, { view:"checkbox", name:"food", label:"Food", checkValue:10 }]
Через свойство checkValue мы задаем
значение отмеченного чекбокса. В нашем случае за дополнительный
багаж и питание пользователю придется доплатить 15 и 10 долларов
соответственно.
Радиокнопки
Теперь давайте перейдем к удобствам полета. За это у нас
отвечают радиокнопки Economy и Business. Реализуются они с помощью
уже знакомого нам элемента radio:
{ view:"radio", name:"class", label:"Class", options:[ { id:1, value:"Economy" }, { id:2, value:"Business" } ]}
Мы установим класс Economy по умолчанию, а при переключении на
Business стандартная цена будет удваиваться. А что вы хотите, за
комфорт нужно платить.
Лейбл
Хороший сервис информативный сервис. Именно поэтому нам нужно
отображать актуальную информацию о стоимости заказа. Давайте
настроим отображение итоговой цены. Реализуется это с помощью уже
знакомого нам компонента label:
{ view:"label", id:"order_price" }
Изначальную цену мы устанавливаем при клике по кнопке Book в
таблице рейсов. Она учитывает стоимость билета и их количество. По
мере добавления плюшек или изменения количество билетов цена будет
пересчитываться автоматически.
Кнопки Go Back и Make Order
Наш пользователь наконец-то определился с заказом и готов его
сделать или передумал и хочет вернуться назад к поиску. Давайте
реализуем такую возможность. Для этого мы создадим соответствующие
кнопки Go Back и Make Order с помощью знакомого нам элемента
button:
{ cols:[ { view:"button", value:"Go Back" }, { view:"button", value:"Make Order" } ] }
Мы создали интерфейс формы заказа рейсов. Давайте поместим его в
наш лейаут и посмотрим, что получилось:
[ toolbar, { cells:[ {...}, { id:"flight_booking", type:"clean", cols:[ order_form, {} ] }]}]
Результат в браузере:

Мы описали все элементы интерфейса и создали лейаут. Теперь
пришло время оживить наше приложения.
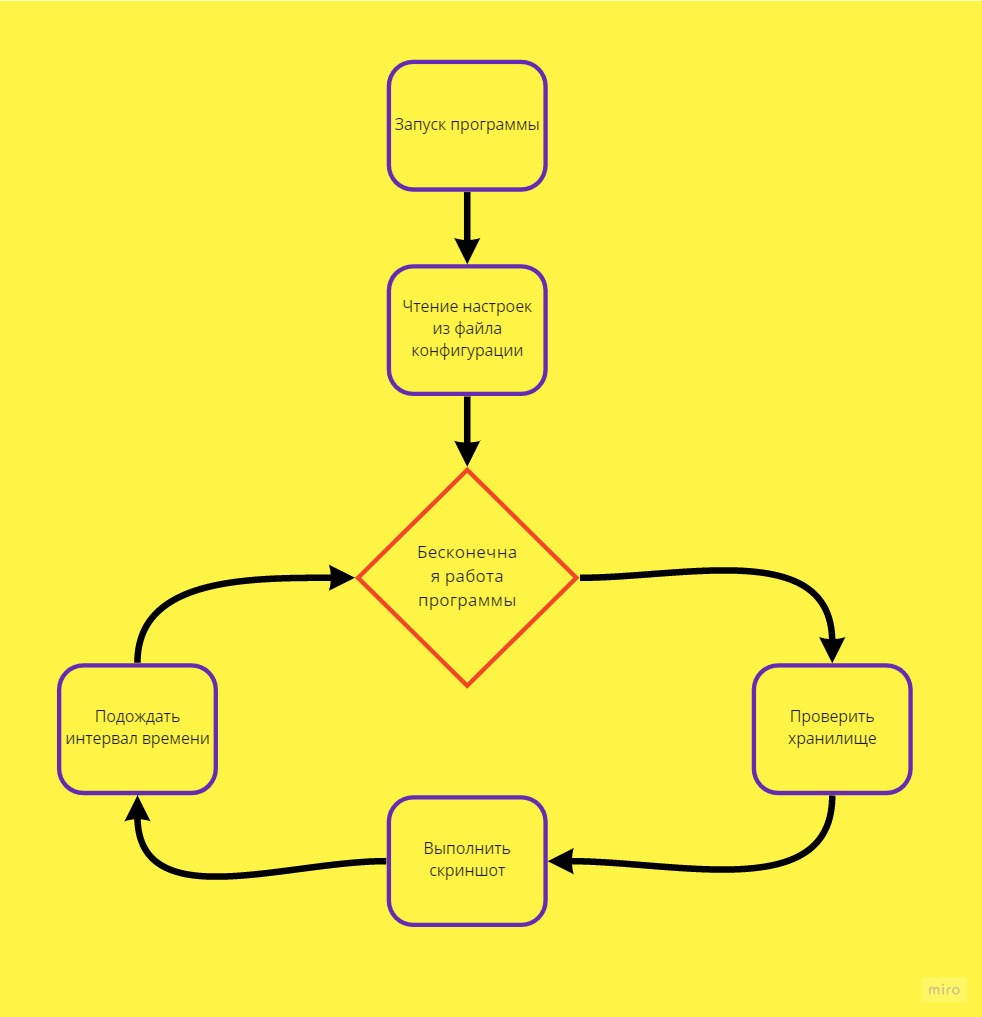
Заставляем приложение работать
В первой части мы описали лейаут и внешний вид компонентов
интерфейса нашего приложения с помощью Webix UI. Но это только
вершина айсберга. Давайте оживим наш проект и сделаем его
интерактивным. Раньше мы только предполагали, что будет, если
пользователь сделает то или иное. Сейчас пришло время осуществить
это на практике, тем более Webix предоставляет нам огромный набор
инструментов для реализации задуманного.
Форма поиска
Радиокнопки
Итак, в самом верху формы поиска у нас находятся радиокнопки
One-Way, которая установлена по умолчанию, и Return, при клике по
которой должен отображаться спрятанный селектор даты возвращения.
Как нам это реализовать? А все очень просто, нужно установить
специальный обработчик на событие переключения между радиокнопками.
Для работы с событиями предусмотрены специальные свойства. Самым
универсальным из них является свойство
on, с помощью которого можно установить
обработчик сразу на несколько событий. Выглядит это следующим
образом:
{ view:"radio", ... on:{ onChange:function(newv){ if(newv == 2){ $$("return_date").show(); //отображаем селектор даты возвращения }else{ $$("return_date").hide(); //прячем селектор даты возвращения } } }}
Теперь при переключении между радиокнопками функция будет
прятать и отображать селектор даты возвращения. Реализуется это с
помощью специальных методов show() и
hide(), названия которых говорят сами за
себя. Универсальный метод
$$(id) позволяет получить доступ к
соответствующему компоненту, id которого передан в
качестве аргумента.
Селекторы городов
Наш пользователь выбрал Берлин в качестве пункта отправления.
После этого он переходит ко второму селектору и видит, что там тоже
есть Берлин. Почему же так случилось? Дело в том, что данные о
городах загружаются из одной коллекции данных. Но пользователя это
не интересует, он не должен иметь возможность искать рейсы из
Берлина в Берлин. Давайте это исправим.
Для того, чтобы выбранная опция одного селектора не повторялась
в списке опций второго, нужно установить специальный обработчик,
который будет анализировать их данные и исключать ненужные.
Делается это при открытии выпадающего списка:
...{ options:cities_data, on:{ onShow:function(v){ optionsData("from","to"); } }}
Снова на помощь приходит свойство on,
которое позволяет устанавливать обработчик на необходимые события.
В нашем случае это событие onShow. При
клике на селектор приложение запустит функцию
optionsData(), которая отфильтрует и
отобразит список доступных опций компонента, для которого она
вызвана. Она имеет следующий вид:
function optionsData(first_id, second_id){ const options = $$(first_id).getList(); //получаем объект значений списка const exception = $$(second_id).getValue(); //получаем выбранное значение options.filter(obj => obj.id != exception); //фильтруем список}
Здесь мы используем такие полезные методы Combo, как
getList() и
getValue(). Первый метод получает список
опций одного селектора, а второй установленное значение другого. С
помощью метода filter() выпадающего листа
функция фильтрует список и исключает из него выбранный город
(полученный методом getValue).
Теперь перейдем к кнопкам Reset и Search.
Кнопка Search
Наш пользователь ввел необходимые условия поиска, кликнул по
кнопке Search и видит результат в таблице рейсов. Такой сценарий
более чем вероятен, поэтому нужно его реализовать. Для этого
необходимо создать и установить обработчик на событие клика по
кнопке. Давайте сначала создадим этот обработчик:
function lookForFlights(){const vals = $$("search_form").getValues(); //получаем объект со значениями полей формыconst table = $$("flight_table"); //получаем доступ к таблице данныхtable.filter(function(obj){ /*условия для фильтрации*/ });}
Одно из множества преимуществ формы Webix заключается в том, что
можно получит значения всех полей сразу в одном объекте.
Реализуется это с помощью метода
getValues(), вызванного для формы.
Полученные значения используются для определения условий фильтрации
в методе filter(), вызванного для таблицы
данных. Метод перебирает элементы данных таблицы, фильтрует их с
помощью условий, полученных из формы, и перестраивает таблицу с
учетом изменившихся данных. Можно только представить, сколько
времени займет реализация подобного функционала на чистом JS.
Итак, обработчик мы создали, сейчас нужно его вызвать на событие
клика по кнопке. Для таких случаев у кнопки предусмотрено свойство
click:
{ view:"button", value:"Search", ... click: lookForFlights }
Кнопка Reset
Бывает,что пользователь уже заполнил форму, но ему нужно
очистить ее и начать заполнять заново, или он уже начал искать и
хочет вернуть таблицу в первоначальное состояние. Такой сценарий
вполне вероятен, поэтому давайте его реализуем при клике по кнопке
Reset.
Для начала нужно создать соответствующий обработчик:
function resetForm(){const form = $$("search_form"); form.clear(); //очищаем формуform.setValues({trip_type:1}); //устанавливаем значения радиокнопки по умолчанию$$("flight_table").filter(); //сбрасываем данные таблицы по умолчанию}
С помощью метода clear(), функция
очищает все поля формы сразу. Но у нас есть поле с типом билета
(прямой или обратный) значение которого нужно установить
по умолчанию. Исправляем этот недочет с помощью метода
setValues(). В качестве аргумента, мы
передаем объект с нужным значением для этого поля.
Выше мы упоминали метод filter() у
таблицы, с помощью которого фильтровали её данные в соответствии с
условиями поиска. Если вызвать этот метод без указания параметров с
условиями, то ее можно сбросить фильтрацию, и тогда ее данные будут
выглядеть как при первоначальной загрузке. Все коротко и ясно. Нет
нужды создавать массу дополнительных функций или перезагружать
приложение. Интуитивно понятные методы значительно упрощают процесс
разработки. Все, что нам осталось, это установить обработчик для
нашей кнопки:
{ view:"button", value:"Reset", ... click:resetForm }
С формой поиска мы разобрались. Давайте перейдем к таблице
рейсов и строке поиска.
Строка поиска
Как вы помните, мы создали строку поиска, с помощью которой
пользователь может искать данные прямо в таблице рейсов.
Чтобы заставить строку поиска работать, нужно добавить
обработчик, который будет сравнивать введенные значения с данными
таблицы и выделять их. Для начала создадим этот обработчик:
function searchFlight(){ //получаем значение строки поискаconst value = $$("search").getValue().toLowerCase(); const table = $$("flight_table"); //формируем объект с совпадениямиconst res = table.find(function(obj){ /*условия поиска*/ }); table.clearCss("marker", true); //убираем предыдущие стилиfor(let i = 0; i < res.length; i++){table.addCss(res[i].id, "marker", true); //вешаем css класс marker}table.refresh(); //перерисовываем таблицу}
Функция получает значение строки поиска через метод
getValue() и сравнивает его с данными
таблицы. Для этого используется метод
find(), вызванный для таблицы рейсов.
Ряды таблицы, значения которых совпали с введенными данными,
помечаются с помощью css класса marker (стили которого
находятся в нашем css файле). После проделанных действий,
нужно обязательно обновить представление с помощью метода
refresh(), чтобы заданный css класс
подсветил нужные ряды.
Теперь необходимо установить этот обработчик на событие
onTimedKeyPress, который будет
обрабатывать значения текстового поля при вводе. Делается это при
помощи знакомого нам свойства on. Код
будет выглядеть следующим образом:
{ view:"search", id:"search", ... on:{ onTimedKeyPress:function(){ //срабатывает при наборе текста searchFlight(); //анализируем данные таблицы и подсвечиваем совпадения }, onChange:function(){ //срабатывает при нажатии на иконку очистить if(!this.getValue()){ $$("flight_table").clearCss("marker"); //убираем подсветку } } }}
Дополнительно, мы установим обработчик на событие
onChange. Он будет срабатывать при клике
по иконке очистить, которую мы установили с помощью свойства
clear, и убирать подсвечивание с
рядов.
Таблица рейсов
На данный момент пользователь уже может искать информацию с
помощью формы поиска и строки поиска, а необходимые рейсы
отображаются и подсвечиваются в таблице.
Как вы помните, напротив каждого рейса мы создали кнопку Book, с
помощью которой пользователь может перейти к форме заказа. Давайте
посмотрим, как организовать переход и какие тут есть дополнительные
нюансы.
Давайте начнем со смены модулей.
При клике на кнопку Book приложение спрячет модуль поиска и
отобразит модуль с формой заказа. Нужно напомнить, что при создании
лейаута, мы использовали компонент
multiview. Наши модули находятся в
массиве свойства cells, и каждому
присвоен соответствующий id:
cells:[ { id:"flight_search", ... }, { id:"flight_booking", ... }]
Смена multiview модулей реализуется с
помощью вызова метода show() для модуля,
который нужно отобразить. Доступ к модулю
мы получаем через универсальный метод
$$(id). В качестве аргумента передаем
id нужного модуля:
$$("flight_booking").show(); //отображаем форму регистрации
Эту строку нам нужно включить в тело нашего обработчика. Давайте
его создадим:
function bookFlight(id){//получаем количество искомых билетовconst required_tickets = $$("search_form").getValues().tickets;//получаем количество свободных местconst available_places = flight_table.getItem(id).places;//устанавливаем максимальное количество билетов $$("tickets_counter").define("max", available_places); //устанавливаем необходимые значения в поля формы регистрации$$("flight_booking_form").setValues({//количество билетов должно быть меньше или соответствовать свободным местамtickets:required_tickets <= available_places ? required_tickets : available_places,//устанавливаем значение цены билета в скрытый инпутprice:flight_table.getItem(id).price,//устанавливаем "Эконом" класс по умолчаниюclass:1});$$("flight_booking").show(); //отображаем форму регистрации...}
Если коротко, то функция получает объект с данными о необходимом
рейсе, устанавливает нужные значения в поля формы заказа и
отображает модуль с формой заказа.
Здесь стоит обратить внимание на такой метод для работы с
таблицей, как getItem(). С его помощью мы
получаем объект значений ряда таблицы, в котором находится кнопка
Book. Из этого объекта мы извлекаем цену билета и количество
свободных мест. В качестве аргумента передаем
id соответствующего ряда.
Как вы помните, при описании тулбара мы определили, что лейбл
будет сменяемым. Сменяться он будет при переходе на другой модуль.
Реализуется это с помощью методов define() и refresh().
Метод define() позволяет изменить
любое свойство компонента, а метод
refresh() обновляет его визуальное
представление:
$$("label").define("label", "Flight Booking"); //меняем лейбл на тулбаре$$("label").refresh(); //обновляем новый лейбл
Теперь нужно установить обработчик на событие клика по кнопке
Book. При создании, мы присвоили ей класс webix_button и
сделали это не просто так. Webix предусматривает
специальный хендлер onClick,
предназначенный для кликов по элементам ячеек таблицы, которые
отмечены тем или иным css классом:
{ columns:[ ], onClick:{ "webix_button":function(e,id){ bookFlight(id); } }}
Теперь все работает и пользователь может переходить к форме
заказа.
Форма заказа
После клика по кнопке Book пользователь переходит к форме
заказа. Выше мы описали, как это реализуется. Теперь давайте
разберемся, что происходит непосредственно в форме заказа. И начнем
мы с системы подсчета стоимости.
Изначальную цену мы устанавливаем при клике по кнопке Book в
таблице рейсов. Она учитывает стоимость билета и их количество. По
мере добавления пользователем плюшек или изменения количества
билетов цена будет пересчитываться автоматически. Чтобы это
реализовать, нам необходимо прибегнуть к старому доброму свойству
on, через которое реализуется подписка на
события onChange (реагирует на изменение
значений пользователем) и onValues
(реагирует на установку значений при клике на кнопку
Book):
on:{onChange:function(){orderPrice(this.getValues());},onValues:function(){orderPrice(this.getValues());}}
Функция имеет следующий вид:
function orderPrice(vals){//получаем количество билетовconst tickets = vals.tickets; //получаем цену с учетом класса и количества билетовconst price = vals.price*1*vals.class*tickets; //получаем стоимость дополнительного багажаconst baggage = vals.baggage * tickets;//получаем стоимость питания const food = vals.food * tickets; //формируем итоговую суммуconst total = price+baggage+food; //отображаем итоговую сумму$$("order_price").setValue(total+"$"); }
Функция-обработчик этих событий получает в качестве аргумента
объект со значениями формы через метод
getValues(), анализирует их и
устанавливает итоговую стоимость внутри лейбла Price через метод
setValue(). В отличие от метода
setValues(), которому можно передать
объект со значениями всех полей формы,
setValue() устанавливает только одно
значение элементу, для которого вызван.
С подсчетом стоимости заказа мы разобрались. Пользователь
добавляет плюшки, а цена автоматически пересчитывается и
отображается.
Теперь пользователь решил сделать заказ, ввел данные и кликнул
по кнопке Make Order. Для того, чтобы определить сценарий
дальнейших действий, нужно создать соответствующий обработчик:
function makeOrder(){const order_form = $$("flight_booking_form"); //получаем доступ к формеif(order_form.validate()){ //запускаем валидацию формыwebix.alert({ //в случае успешной валидации выводим сообщение о заказеtitle: "Order",text: "We will send you an information to confirm your Order"}).then(function(){goBack(); //очищаем валидацию и возвращаемся к таблице рейсов});}}
Функция запускает валидацию формы при помощи метода
validate(). Этот метод анализирует
значения полей формы, для которых мы установили правила в свойстве
rules. Если значения полей соответствуют
правилам, валидация пройдет успешно и метод вернет
true. В противном случае метод вернет
false, поля с некорректными данными
подсветятся красным, а внизу появятся сообщения об ошибках.
Напомню, что эти сообщения мы определяем через свойство
invalidMessage.
В случае успешной валидации функция выведет сообщение о
готовности заказа. Здесь стоит сказать, что Webix имеет несколько
методов для вывода сообщений. Мы будем использовать webix.alert(),
для которого можно указать действия, которые выполнятся при нажатии
на кнопку OK метода (в нашем случаи это функция
goBack()):
webix.alert({ title: "Order is successfull", text: "We will send you an information to confirm your Order"}).then(function(){ goBack();});
Функцию goBack() мы также
устанавливаем в качестве обработчика на кнопку Go Back. Она очищает
валидацию с помощью метода
clearValidation(), изменяет лейбл
тулбара, а также возвращает нас в модуль с таблицей рейсов и формой
поиска:
function goBack(){const order_form = $$("flight_booking_form"); //получаем доступ к формеconst label = $$("label"); //получаем доступ к лейблу на тулбареorder_form.clearValidation(); //очищаем валидациюlabel.define("label", "Flight Search"); //изменяем значение лейблаlabel.refresh(); //обновляем лейбл$$("flight_search").show(); //отображаем лейаут с таблицей рейсов и формой поиска}
Заключение
С кодом готового приложения можно ознакомиться тут.
В этой статье мы детально разобрали, как создать приложение с
использованием Webix. Научились создавать лейауты и описывать UI
компоненты с помощью json синтаксиса. Косвенно затронули некоторые
методы, которые позволяют работать с данными. Как вы могли
убедиться, компоненты и методы интуитивно понятны и просты в
использовании. На самом деле, это только малая толика всего, что
может предложить нам библиотека. Для более детального ознакомления
можно перейти к документации, в которой
есть подробное описание всех возможностей с наглядными
примерами.























 Рабочий стол с ярлыком
Рабочий стол с ярлыком  Главное окно приложения
Главное окно приложения Панель задач
Панель задач




 Создание String-переменной
Создание String-переменной
 Переводы для интерфейсов
Переводы для интерфейсов
 Макет
Activity_Settings.xml
Макет
Activity_Settings.xml Макет
Activity_Advanced.xml
Макет
Activity_Advanced.xml





 Рис.1. Ожидаемый результат
Рис.1. Ожидаемый результат
 Рис.2. Хороший результат
Рис.2. Хороший результат
 Рис.3. Ржачный результат
Рис.3. Ржачный результат