

Правда, не следует думать, что то, о чём мы будем тут говорить, подобно простому примеру, вроде
println(Hello world),
в котором используется система акторов Akka. Сегодня вы узнаете о
том, как создать свой первый сервис для потоковой передачи видео
(прошу прощения, если моё предположение неверно, и у вас это уже не
первый такой проект). В частности, тут будут использованы пакеты
Akka HTTP и Akka Streams, с помощью которых мы создадим REST API,
который обладает способностями стриминга видеофайлов в формате MP4.
При этом устроен этот API будет так, чтобы то, что он выдаёт,
соответствовало бы ожиданиям HTML5-тега <video>.
Кроме того, тут я скажу несколько слов о наборе инструментов Akka в
целом, и о некоторых его компонентах, вроде Akka Streams. Это даст
вам определённый объём теории, которая пригодится вам в работе. Но,
прежде чем мы приступим к делу, хочу задать один вопрос.Почему я решил рассказать о стриминге видео?
У того, что я посвятил эту статью потоковой передаче видео, есть три основных причины.
Первая причина заключается в том, что это, с моей точки зрения, захватывающая и сложная тема. Особенно если речь идёт о крупномасштабных стриминговых сервисах (вроде Netflix). Мне всегда хотелось получше разобраться в этой теме.
Вторая причина это то, что потоковая передача видео представляет собой нишевую задачу. Поэтому проект, имеющий какое-то отношение к стримингу видео, может стать отличным дополнением к портфолио любого разработчика. В нашем же случае это особенно актуально для тех, кто хочет познакомиться с миром Scala и Akka.
И третья причина, последняя в моём списке, но такая же важная, как и другие, кроется в том, что разработка стримингового сервиса это очень интересный способ знакомства с библиотекой Akka Streams, которая, на самом деле, значительно упрощает задачу создания подобного сервиса.
А теперь мы можем переходить к нашей основной теме.
Что такое набор инструментов Akka? Удобно ли им пользоваться?
Akka это опенсорсный набор инструментов, который нацелен на упрощение разработки многопоточных и распределённых приложений, и, кроме того, даёт программисту среду выполнения для подобных приложений. Системы, которые базируются на Akka, обычно очень и очень хорошо масштабируются. Проект Akka основан на модели акторов, в нём используется система конкурентного выполнения кода, основанная на акторах. Создатели этого проекта многое почерпнули из Erlang. Инструменты Akka написаны на Scala, но в проекте имеются DSL и для Scala, и для Java.
Если говорить об удобстве работы с Akka, то, полагаю, писать код с использованием этого набора инструментов весьма удобно. Если вы хотите получше его изучить рекомендую начать с этого материала.
Основной объём кода, который мы будем тут рассматривать, будет использовать пакеты HTTP и Streams. Мы практически не будем пользоваться стандартным пакетом Akka Actors.
Теперь, когда мы разобрались с самыми базовыми сведениями об Akka, пришло время вплотную заняться пакетом Akka Streams.
Что такое Akka Streams?
Akka Streams это всего лишь пакет, построенный на базе обычных акторов Akka. Он нацелен на то, чтобы облегчить обработку бесконечных (или конечных, но очень больших) последовательностей данных. Главной причиной появления Akka Streams стали сложности правильной настройки акторов в системе акторов, обеспечивающей стабильную работу с данными при их потоковой передаче.
Для нас важен тот факт, что в Akka Streams есть встроенный механизм back-pressure (обратное давление). Благодаря этому решается одна из самых сложных проблем мира стриминговой передачи данных. Это настройка правильной реакции поставщика данных на работу в условиях, когда потребитель данных не может справиться с нагрузкой. И эту проблему решает инструмент, которым мы будем пользоваться, а нам остаётся лишь научиться работать с этим инструментом, не вдаваясь в какие-то чрезмерно сложные и запутанные темы.
Пакет Akka Streams, кроме того, даёт в наше распоряжение API, который совместим с интерфейсами, необходимыми для работы с Reactive Streams SPI. И, между прочим, стоит отметить, что сам проект Akka входит в число основателей инициативы Reactive Streams.
Про Akka Streams мы поговорили. Поэтому можем переходить к нашей следующей теоретической теме.
Что такое Akka HTTP?
Akka HTTP это, как и Akka Streams, пакет, входящий в набор инструментов Akka. Этот пакет основан на пакетах Akka Streams и Akka Actors. Он направлен на то, чтобы упростить работу приложений, в которых используются инструменты Akka, с внешним миром по протоколу HTTP. Этот пакет поддерживает и серверные, и клиентские возможности. Поэтому с его помощью можно создавать и REST API, и HTTP-клиентов, которые отправляют запросы к неким внешним сервисам.
Теперь, когда у вас должно сложиться общее представление об инструментах, которыми мы будем пользоваться при создание бэкенда нашего проекта, осталось лишь поговорить о самой важной составляющей фронтенда нашего приложения.
HTML5-тег <video>
Тег
<video> это новый элемент, который появился
в HTML5. Он создавался как замена Adobe Video Player. Несложно
понять, что главная задача этого HTML-элемента заключается в
предоставлении разработчикам возможностей встраивания в
HTML-документы медиаплееров, способных воспроизводить видеофайлы.
Собственно, этот тег очень похож на <img>.В теге
<video> размещают тег
<source>, имеющий два важных атрибута. Первый
это src, который используется для хранения ссылки на
видео, которое нужно воспроизвести. Второй это type,
который содержит сведения о формате видео.Между открывающим и закрывающим тегом
<video>
</video> можно ввести какой-то текст, который
будет использован в роли текста, выводимого вместо элемента
<video> в тех случаях, когда этот элемент не
поддерживается браузером. Но в наши дни тег
<video> поддерживает даже Internet Explorer,
поэтому вероятность возникновения ситуации, в которой может
понадобиться подобный текст, стремится к нулю.Как будет работать стриминг с
использованием тега и FileIO?</font></h2>Хотя на первый
взгляд кажется, что стриминг с использованием тега <video> и
FileIO это нечто архисложное, если в этот вопрос немного вникнуть,
окажется, что ничего особенного в нём нет. Дело в том, что то, о
чём идёт речь, представлено готовыми блоками, из которых нужно лишь
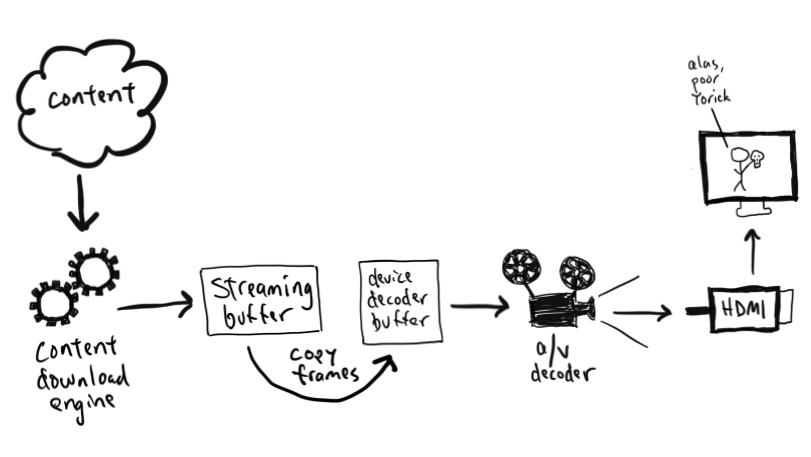
собрать то, что нам нужно.На стороне сервера основная нагрузка
ложится на объект <code>FileIO</code>. Он будет
генерировать события, содержащие фрагменты файла, потоковую
передачу которого мы осуществляем. Конечно, размеры этих фрагментов
поддаются настройке. И, более того, настроить можно и позицию,
начиная с которой будет осуществляться стриминг файла. То есть
видео необязательно смотреть сначала его можно начинать смотреть с
любого места, интересующего пользователя. Всё это отлично
сочетается с возможностями тега
<code><video></code>, выполняющего запрос HTTP
GET с заголовком <code>Range</code> для того чтобы
включить воспроизведение видео без его предварительной загрузки.Вот
пара примеров запросов, выполняемых элементом
<code><video></code>:<img
src="http://personeltest.ru/aways/lh3.googleusercontent.com/Dfgd_RjgpV9W3jzBF9TVNLT_n8cAf5_VfvhxbfeK5wYH5slwUtXhjQ0FlZ0I79gCWsNgIF1Q3q7nPty5HqpCpgXIYrEtjQINuyMaMHe1nWu228-p8o9Hf3n-cHNZN_5iS0QGktk"
align="center"><img
src="http://personeltest.ru/aways/lh3.googleusercontent.com/SQPBs8xy8HVsT8cw2_WRoOnQW1dqKRp2WVSAzfFsbCBkSmETbm7NKS8zMLBdwcWdIo1AQDO_tSJJw1_2Tcd_oMoaBzdTwDz62Tq2jtzKX0ujmuCEqo99NKH_YLnlL6FQbZ5UOd0"
align="center">Если кому интересно заголовок
<code>Range:bytes=x-</code> отвечает за выбор позиции,
с которой начинается воспроизведение видео. Первый запрос уходит на
сервер в начале воспроизведения видео, а второй может быть
отправлен тогда, когда пользователь решит куда-нибудь перемотать
видео.Сейчас, после довольно-таки длинного вступления, пришло время
заняться кодом.<h2><font color="#3AC1EF">Пишем
стриминговый сервис</font></h2>В нескольких следующих
разделах я расскажу о реализации серверной части нашего
стримингового сервиса. А потом мы создадим простую HTML-страницу, с
помощью которой проверим правильность работы этого сервиса.Я люблю
делать предположения, поэтому сделаю ещё одно, которое заключается
в том, что я ожидают, что тот, кто это читает, владеет основами
Scala и SBT.<h3><font
color="#3AC1EF">1</font></h3>Добавим в файл
<code>build.sbt</code> необходимые зависимости. В этом
проекте нам понадобится 3 пакета:
<code>akka-http</code>,
<code>akka-actor-typed</code> (пакета
<code>akka-actor</code>, в теории, достаточно, но
никогда нельзя забывать о типобезопасности) и
<code>akka-stream</code>.<source
lang="scala">libraryDependencies ++= Seq("com.typesafe.akka" %%
"akka-actor-typed" % "2.6.14","com.typesafe.akka" %% "akka-stream"
% "2.6.14","com.typesafe.akka" %% "akka-http" %
"10.2.4")</source><h3><font
color="#3AC1EF">2</font></h3>Теперь можно создать
главный класс, ответственный за запуск приложения. Я решил
расширить класс <code>App</code>. Мне кажется, что это
удобнее, чем создавать метод <code>main</code>. На
следующем шаге мы поместим сюда код, имеющий отношение к созданию
системы акторов и HTTP-сервера.<source lang="scala">object
Runner extends App {}</source><h3><font
color="#3AC1EF">3</font></h3>После создания главного
класса мы можем добавить в него код, о котором говорили
выше.<source lang="scala">object Runner extends App {val
(host, port) = ("localhost", 8090)implicit val system:
ActorSystem[Nothing] = ActorSystem(Behaviors.empty,
"akka-video-stream")Http().newServerAt(host,
port)}</source>Сейчас нас вполне устроит такая конфигурация.
На последнем шаге мы добавим в код вызов метода
<code>bind</code>, что позволит открыть доступ к нашему
REST API. Тут мы создаём объект
<code>ActorSystem</code> с именем
<code>akka-video-stream</code> и HTTP-сервер,
прослушивающий порт <code>8090</code> на локальном
компьютере. Не забудьте о ключевом слове
<code>implicit</code> в определении системы акторов,
так как подобный неявный параметр необходим в сигнатуре метода
<code>Http</code>.<h3><font
color="#3AC1EF">4</font></h3>А тут мы, наконец,
реализуем конечную точку REST API, используемую для обработки
запросов от тега <code><video></code>.<source
lang="scala">object Streamer {val route: Route =path("api" /
"files" / "default") {get {optionalHeaderValueByName("Range") {case
None =>complete(StatusCodes.RangeNotSatisfiable)case Some(range)
=> complete(HttpResponse(StatusCodes.OK))}}}}</source>Как
видите, я создал конечную точку с URL
<code>api/files/default/</code>. В её коде проверяется,
есть ли в запросе заголовок <code>Range</code>. Если он
содержит корректные данные сервер возвращает ответ с кодом
<code>200</code> (<code>OK</code>). В
противном случае возвращается ответ с кодом
<code>416</code> (<code>Range Not
Satisfiable</code>).<h3><font
color="#3AC1EF">5</font></h3>Пятый шаг нашей работы
отлично подходит для реализации метода, ради которого, собственно,
и была написана эта статья.<source lang="scala">private def
stream(rangeHeader: String): HttpResponse = {val path =
"path/to/file"val file = new File(path)val fileSize =
file.length()val range = rangeHeader.split("=")(1).split("-")val
start = range(0).toIntval end = fileSize - 1val headers =
List(RawHeader("Content-Range", s"bytes
${start}-${end}/${fileSize}"),RawHeader("Accept-Ranges",
s"bytes"))val fileSource: Source[ByteString, Future[IOResult]] =
FileIO.fromPath(file.toPath, 1024, start)val responseEntity =
HttpEntity(MediaTypes.`video/mp4`,
fileSource)HttpResponse(StatusCodes.PartialContent, headers,
responseEntity)}</source>Тут я сделал
следующее:<ul><li>Загрузил файл, потоковую передачу
которого я хочу организовать, а затем, учитывая заголовок из
запроса, и данные о файле, нашёл позицию в файле, с которой
начнётся стриминг, а так же сформировал заголовок
<code>Content Range</code>.</li><li>С
помощью <code>FileIO</code> создал поток из ранее
загруженного файла. Затем я использовал этот поток в роли данных в
<code>HttpEntity</code>.</li><li>Я создал
ответ, <code>HttpResponse</code>, с кодом
<code>206</code> (<code>Partial
Content</code>), с соответствующими заголовками и с телом в
виде
<code>responseEntity</code>.</li></ul>Ещё
мне хочется подробнее поговорить о <code>FileIO</code>,
так как это самый удивительный механизм во всей статье. Что, на
самом деле, происходит при выполнении строки
<code>FileIO.fromPath(file.toPath, 1024,
start)</code>?Тут, из содержимого файла, находящегося по
заданному пути, создаётся объект <code>Source</code>
(Akka-аналог Producer из Reactive Streams). Каждый элемент,
выдаваемый этим объектом, имеет размер, в точности равный 1 Мб.
Первый элемент будет взят из позиции, указанной в параметре
<code>start</code>. Поэтому, если в <code>start
</code>будет 0 первый элемент окажется первым мегабайтом
файла.<h3><font
color="#3AC1EF">6</font></h3>Мы уже реализовали
основную логику серверной части приложения. А сейчас нам надо
отрефакторить её код для того чтобы нашим сервером можно было бы
пользоваться.Начнём с внесения изменений в определение REST
API:<source>complete(HttpResponse(StatusCodes.Ok)) =>
complete(stream(range))</source>Получается, что вместо того,
чтобы просто возвращать <code>OK</code>, мы вызываем
метод <code>stream</code> с передачей ему параметра
<code>range</code> и начинаем стриминг.Нельзя забывать
о том, что наш API всё ещё недоступен для внешнего мира. Поэтому
нам нужно модифицировать соответствующий фрагмент кода,
ответственный за запуск
HTTP-сервера:<source>Http().newServerAt(host, port)
=>Http().newServerAt(host,
port).bind(Streamer.route)</source>Готово! Теперь у нас есть
рабочий бэкенд, а наш REST API ждёт подключений от любых программ,
которым он нужен. Осталось лишь всё
протестировать.<h2><font color="#3AC1EF">Тестирование
стримингового сервиса</font></h2>Мы, чтобы
протестировать приложение, создадим простую HTTP-страницу,
единственным достойным внимания элементом которой будет тег
<code><video></code>. Причём, обо всём, что надо
знать для понимания работы этой страницы, мы уже говорили. Поэтому
я просто приведу ниже полный код соответствующего
HTML-документа.То, что вы в итоге увидите в окне браузера, открыв
эту страницу, должно, более или менее, напоминать то, что я покажу
ниже. Конечно, ваш стриминговый сервис вполне может передавать не
тот видеофайл, который использовал я.<source
lang="html"><!DOCTYPE html><html
lang="en"><head><title>Akka streaming
example</title></head><body style="background:
black"><div style="display: flex; justify-content:
center"><video width="1280" height="960" muted autoplay
controls><source
src="http://personeltest.ru/away/localhost:8090/api/files/default"
type="video/mp4">Update your browser to one from XXI
century
Тут мне хотелось бы обратить ваше внимание на 5 важных вещей:
- Я использовал возможности тега
<source>вместо использования соответствующих атрибутов тега<video>. - В атрибуте
srcтега<source>я указал путь, при обращении к которому бэкенд начнёт потоковую передачу видеофайла. - В атрибуте
typeтега<source>я указал тип файла. - Я добавил к тегу
<video>атрибутыautoplayиmutedдля того чтобы видео начинало бы воспроизводиться автоматически. - К тегу
<video>я добавил и атрибутcontrols, благодаря чему будут выводиться элементы управления видеоплеера, встроенного в страницу.
На элемент
<div> можете особого внимания не
обращать. Он тут нужен лишь для стилизации плеера.Для проверки правильности работы системы достаточно запустить бэкенд и открыть вышеописанный HTML-документ в любом современном браузере.

Правильная работа стримингового сервиса
Обратите внимание на то, что автоматическое воспроизведение видео не начнётся до тех пор, пока к тегу
<video> не
будут добавлены атрибуты muted и
autoplay. Если не оснастить тег
<video> этими атрибутами воспроизведение
придётся включать вручную, нажимая на соответствующую кнопку.Как и в любом обычном программном проекте, мы, после создания и тестирования первого варианта программы, можем переосмыслить решения, принятые в самом начале, и подумать о том, как улучшить её код.
Что можно улучшить?
На самом деле, если вы не собираетесь организовывать стриминг нескольких файлов, то в нашем проекте менять особо и нечего. Конечно, путь к видеоклипу можно переместить в какой-нибудь конфигурационный файл. Но я не могу придумать направления каких-то-то более серьёзных улучшений этого проекта.
Если же вы хотите организовать стриминг нескольких файлов это значит, что вы можете реализовать нечто наподобие хранилища контента, а после этого создать отдельный сервис, ответственный за обращение к этому хранилищу и за возврат файлов. Ещё можно переделать существующую конечную точку так, чтобы она поддерживала бы передачу стриминговому сервису имени файла, вместо того, чтобы использовать имя, жёстко заданное в коде. А потом можно реализовать некую систему преобразования переданных имён в пути к видеофайлам.
Итоги
Сегодня я постарался доказать то, что реализация простого стримингового сервиса это, при условии использования правильных инструментов, проще, чем кажется. Использование инструментов Akka и подходящего HTML-тега способно значительно сократить объём работы. Правда, не забывайте о том, что тут показан очень простой пример. Для реализации реального стримингового сервиса этого может быть недостаточно.
В любом случае надеюсь, что вы, читая эту статью, узнали что-то новое, или, что мне удалось углубить ваши знания в некоторых из обсуждённых тут вопросов.
Вот GitHub-репозиторий с кодом проекта.
Какие инструменты вы выбрали бы для создания собственного стримингового сервиса?






















































 Фотография: Leon Bublitz. Источник: Unsplash.com
Фотография: Leon Bublitz. Источник: Unsplash.com
 Фотография: lucas Favre. Источник: Unsplash.com
Фотография: lucas Favre. Источник: Unsplash.com












 Фотография: Anne Nygrd. Источник: Unsplash.com
Фотография: Anne Nygrd. Источник: Unsplash.com
 Фотография: gotafli. Источник: Unsplash.com
Фотография: gotafli. Источник: Unsplash.com
 Фотография: Dodi Achmad. Источник: Unsplash.com
Фотография: Dodi Achmad. Источник: Unsplash.com
 Фотография: Gabriele Diwald. Источник: Unsplash.com
Фотография: Gabriele Diwald. Источник: Unsplash.com
 Фотография: Annie Spratt. Источник: Unsplash.com
Фотография: Annie Spratt. Источник: Unsplash.com
 Фотография: ConvertKit. Источник: Unsplash.com
Фотография: ConvertKit. Источник: Unsplash.com
 Фотография: Advantage Video Productions.
Источник: Unsplash.com
Фотография: Advantage Video Productions.
Источник: Unsplash.com
 Фотография: NeONBRAND. Источник: Unsplash.com
Фотография: NeONBRAND. Источник: Unsplash.com
 Фотография: Kelly Sikkema. Источник: Unsplash.com
Фотография: Kelly Sikkema. Источник: Unsplash.com
 Фотография: Dominik Vanyi. Источник: Unsplash.com
Фотография: Dominik Vanyi. Источник: Unsplash.com
 Фотография: Omar Prestwich. Источник: Unsplash.com
Фотография: Omar Prestwich. Источник: Unsplash.com















 Видеомикшеры поддерживают функции
хромакея, и уже в младшей версии устройства имеется возможность
объединения трех источников в единый видеопоток, без необходимости
дополнительного оборудования.
Видеомикшеры поддерживают функции
хромакея, и уже в младшей версии устройства имеется возможность
объединения трех источников в единый видеопоток, без необходимости
дополнительного оборудования. Далее, начиная с базовой модели,
присутствует возможность создания готовых пресетов, вызывая которые
во время эфира или подстраиваясь на ходу, можно объединять картинку
в картинке, применять совмещение или разбиение экрана (split
screen).
Далее, начиная с базовой модели,
присутствует возможность создания готовых пресетов, вызывая которые
во время эфира или подстраиваясь на ходу, можно объединять картинку
в картинке, применять совмещение или разбиение экрана (split
screen).
 А в расширенной модели VR-50HD MK II уже
есть удаленное управление подключенными PTZ камерами, позволяя
управлять шестью PTZ камерами одновременно по сети. Выходных
интерфейсов три Program, Multiview, а также AUX, позволяя
перенаправлять любой подключенный сигнал на данный выход, который
работает независимо от основного программного выхода.
А в расширенной модели VR-50HD MK II уже
есть удаленное управление подключенными PTZ камерами, позволяя
управлять шестью PTZ камерами одновременно по сети. Выходных
интерфейсов три Program, Multiview, а также AUX, позволяя
перенаправлять любой подключенный сигнал на данный выход, который
работает независимо от основного программного выхода.



 Все компактные микшеры данного
производителя поддерживают эффектные переходы, возможность
наложения титров, бесплатное программное обеспечение ATEM Software
Control для удаленного управления с компьютера, плюсом имеется
возможность разрабатывать собственные продукты с помощью пакета
SDK.
Все компактные микшеры данного
производителя поддерживают эффектные переходы, возможность
наложения титров, бесплатное программное обеспечение ATEM Software
Control для удаленного управления с компьютера, плюсом имеется
возможность разрабатывать собственные продукты с помощью пакета
SDK. Средняя модель Pro имеет все
характеристики базовой версии, но уже обладает возможностью
стриминга непосредственно в H.264 через Ethernet порт. Порт HDMI в
данном случае используется для режима multiview, на котором можно
отобразить: сигналы preview, program, каждый входной сигнал,
медиаплеер с выбранной графикой, состояние записи, трансляции и
аудиоблока.
Средняя модель Pro имеет все
характеристики базовой версии, но уже обладает возможностью
стриминга непосредственно в H.264 через Ethernet порт. Порт HDMI в
данном случае используется для режима multiview, на котором можно
отобразить: сигналы preview, program, каждый входной сигнал,
медиаплеер с выбранной графикой, состояние записи, трансляции и
аудиоблока. А расширенная модель Pro ISO позволяет
производить запись пяти сигналов программного и чистых сигналов с
входов для дальнейшего монтажа.
А расширенная модель Pro ISO позволяет
производить запись пяти сигналов программного и чистых сигналов с
входов для дальнейшего монтажа. Еще одна компания, основанная в 1979 году
в Тайвани, идущая с девизом просто лучшие соединения
позиционируется на рынке как производитель коммутационного
оборудования. В дополнении к уже существующему оборудованию,
представила удивительно-компактный видеомикшер, чтобы не отставать
от тенденций развития потокового контента на рынке.
Еще одна компания, основанная в 1979 году
в Тайвани, идущая с девизом просто лучшие соединения
позиционируется на рынке как производитель коммутационного
оборудования. В дополнении к уже существующему оборудованию,
представила удивительно-компактный видеомикшер, чтобы не отставать
от тенденций развития потокового контента на рынке.

 Итак, идеология устройства позволяет
захватывать видео сигнал с двух физических интерфейсов, один из
которых поддерживает 4K-разрешения, а другой (с доп. проходным
выходом) только fullHD разрешения. При этом суть поддержки камер с
разрешение 4K в том, чтобы можно было сделать 4 вырезки кадров из
одного потока, тем самым получив 4 различных картинки (как будто у
вас 4 входных видео потока).
Итак, идеология устройства позволяет
захватывать видео сигнал с двух физических интерфейсов, один из
которых поддерживает 4K-разрешения, а другой (с доп. проходным
выходом) только fullHD разрешения. При этом суть поддержки камер с
разрешение 4K в том, чтобы можно было сделать 4 вырезки кадров из
одного потока, тем самым получив 4 различных картинки (как будто у
вас 4 входных видео потока). Видеомикшер позволяет как транслировать
потоковый контент в H.264 по сети через Ethernet, так и записывать
этот контент на SD-карту, разъем которого предусмотрен на лицевой
части видеомикшера.
Видеомикшер позволяет как транслировать
потоковый контент в H.264 по сети через Ethernet, так и записывать
этот контент на SD-карту, разъем которого предусмотрен на лицевой
части видеомикшера. Особенностью данного микшера является
возможность съемки, обработки и трансляции видео контента не только
в привычном landscape режиме, но и в портретном, что популярно для
съемки или просмотра со смартфонов.
Особенностью данного микшера является
возможность съемки, обработки и трансляции видео контента не только
в привычном landscape режиме, но и в портретном, что популярно для
съемки или просмотра со смартфонов.










