В этой статье я хочу вернуться на несколько лет назад, пройти
еще раз наш путь развития в разработке интерфейсов для систем
управления и диспетчеризации, и поделиться своим опытом.
Я уже больше 10 лет занимаюсь автоматизацией и диспетчеризацией
инженерных систем, у меня небольшая команда
специалистов, и так сложилось, что мы уделяем большое внимание не
только тому, как системы работают внутри, но и как с ними будет
взаимодействовать персонал.
В том году я уже писал статью об
интерфейсах систем диспетчеризации, она получилась большая, и в ней
все рассказано в общих чертах, здесь же я хочу рассказать более
конкретно о своих наработках и своем опыте. Буду придерживаться в
первую очередь систем вентиляции, так как они чаще всего
встречаются на объектах и по ним больше наработок. Так же, будут
примеры с разных устройств: панелей 7 дюймов и широкоформатных
мониторов.
В этой статье я не буду акцентировать внимание на производителях
оборудования и софта, так как это имеет второстепенное значение.
Интерфейс разрабатывается в графическом редакторе под нужное
разрешение и размер экрана, и уже после интегрируется в нужный
софт. Хотя по многим скриншотам можно узнать производителя, в этом
плане мы довольно консервативны и привыкли работать с тем, что уже
знаем вдоль и поперек.
Лонгрид!
2014

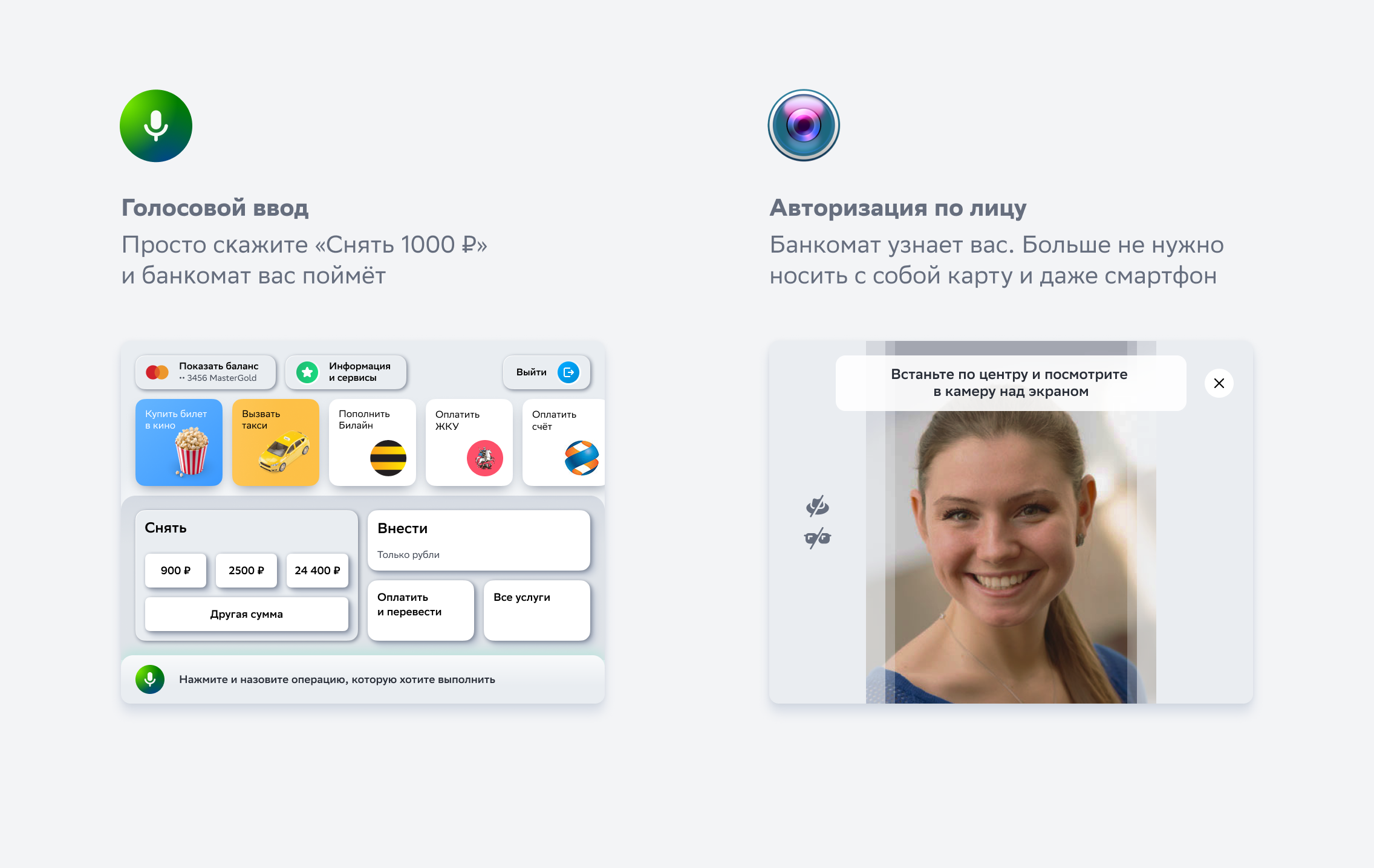
Главное окно с мнемосхемой на сенсорной
панеле управления 7 дюймов

Основное меню с настройками на сенсорной
панеле управления 7 дюймов

Окно диспетчеризации, можно открыть на
любом устройстве под управлением Windows
Это индивидуальный тепловой пункт одного из павильонов ВДНХ в
Москве, первый самостоятельный объект, где можно было проявить
творческий подход. В помещении ИТП на шкафу управления установлена
7 дюймовая сенсорная панель для локального управления и облачная
система диспетчеризации. Несмотря на то, что в этом интерфейсе
довольно все криво и сыро, здесь есть много элементов и правил,
которым мы придерживаемся до сих пор.
С самого первого объекта я начал применять темный интерфейс. У
специализированных программ (AutoCad, Photoshop), был темно-серый
интерфейс, в нем было комфортно работать долгое время и я решил
придерживаться их идеологии. К тому же, помещение ИТП было без
освещения и очень темным, делать яркий светлый фон на панеле просто
издевательство над эксплуатацией. Хотя сейчас у нас в портфолио
есть кейсы со светлой темой, все равно, на сегодняшний день
предпочтение отдается именно темной.
Иконки и анимация были сделаны с нуля под этот объект, их сделал
дизайнер фрилансер, сразу пачкой под разные системы. Иконки
трехмерные, чистые и аккуратные, с синим акцентом, применялись на
многих объектах и вносили свой определенный стандарт и
узнаваемость. Готовые библиотеки иконок и анимаций у всех
производителей очень разные и, как правило, не очень высокого
качества, и уже тогда не было желания ими пользоваться. Сейчас мы
эти иконки не используем, так как полностью отказались от любых
трехмерных изображений.
Наименьшим изменениям за все время подверглось меню панели
управления. Сейчас мы точно так же размещаем в левой колонке пункты
меню, а в правой содержимое вкладки.
Все элементы интерфейса: статика и переменные, собирались внутри
программного обеспечения производителя панелей или диспетчеризация.
В них крайне неудобно выравнивать объекты, не удобная сетка, от
этого все гуляет и сами интерфейсы могут сильно отличаться друг от
друга.
Тогда уже было понимание, что переменные должны быть крупнее и
контрастнее на мнемосхеме и должны визуально отличаться от других
объектов. Понимание было, а реализация хромала. На тот момент,
лучше, чем синяя обводка значения переменной я не придумал. Синий
цвет акцента пришел в интерфейс с сайта, сперва в иконки, а потом
уже в обводку и некоторые другие элементы. На тот момент синий цвет
не имел какой-то определенной задачи в интерфейсе и добавлялся по
принципу "а почему бы и не синий". Но, тем не менее, он
присутствует в наших интерфейсах и по сей день.
2015

Приточно-вытяжная установка с гликолевым
рекуператором. Панель оператора 10 дюймов.
В этом году в плане дизайна ничего сильно не изменилось, те же
цвета, так же много трехмерных картинок и так же все элементы
гуляют кто куда. На этом этапе развития не уделяли внимания
сокращениям и подписям. Все подписи сокращались, чтобы вписать в
интерфейс. На этих примерах нет даже банального обозначения
градусов и температуры у переменных. С точки зрения разработчиков
систему управления это серьезный промах, и надо признать, что
должное внимание этому стали уделять довольно поздно.
Синий цвет здесь по-прежнему использовался без назначения, от
этого не понятно, с чем возможно взаимодействовать, а что просто
статичный элемент.
В общем и целом интерфейс свою задачу выполняет и он не слишком
плох. Самая большая его проблема это отступы и выравнивание.
Особенно это видно по зеленым индикаторам, они разбежались кто
куда. Если этот же интерфейс отрисовать в фотошопе и выровнять все
объекты аккуратно по сетке и друг относительно друга, будет совсем
другая картина.
2016

Станция ВЗУ коттеджного поселка. Панель
оператора 10 дюймов.

В 2016 году я продолжил использовать трехмерные картинки, синий
цвет и добавил еще больше обводок. В целом интерфейсы получались
симпатичными и достаточно удобными для персонала. И он уже выглядит
значительно лучше, чем предыдущий.
На объектах, где есть технология, возникают проблемы в отрисовке
из-за использования трехмерной графики. Одно дело показать насосы,
клапан, фильтры и заслонки, другое дело показать технологическое
оборудование. Найти в интернете подходящие картинки
ультрафиолетовых ламп и фильтров очистки крайне сложно, не говоря
уже о более сложном оборудовании: флотаторы, жироловки,
обезвоживатели и так далее. Это одна из причин, почему мы
отказались от 3Д в дальнейшем.
Структура меню не изменилась, изменился немного дизайн.
Добавились иконки в пунктах меню. Иконки декоративные, какой-то
пользы они не несут, скорее просто иконки ради иконок. Здесь они
крупные, выполнены в стиле Flat, занимают прилично место на экране.
В дальнейшем от иконок мы не отказывались, они стали меньше и
аккуратнее и лучше вписываются в общую стилистику. Стоит применять
иконки или нет в пунктах меню ответить однозначно сложно. Думаю,
что так же как и с 3Д картинками, не под все пункты меню можно
подобрать подходящие по стилю и смыслу иконки. Если есть
возможность добавить аккуратные иконки, не уменьшая полезную
площадь подписей, то лучше их добавить, они разбавят табличную
структуру меню.
Еще один довольно важный момент. В этих интерфейсах не было
визуального отличия переменных чтения от переменных записи. Для
того чтобы понять, уставка это или индикация значения, нужно было
нажать на нее и посмотреть выскочит ли экранная клавиатура для
ввода.
2017

Производственно-складской комплекс, МО,
обзорная схема, 27 дюймов

Производственно-складской комплекс, МО,
под экран планшета и ноутбука

В начале года был довольно крупный объект, комплексная
диспетчеризация производственно-складского комплекса. Этот клиент
дал много опыта с точки зрения инженерных систем и алгоритмов
управления, но сделать что-то принципиально новое в интерфейсе на
тот год не вышло. В этом интерфейсе применяли все уже предыдущие
наработки, немного дорабатывая и улучшая. Здесь уже есть какое-то
выравнивание. Отступы гуляют по-прежнему, но, в целом, сетка
объектов прослеживается, от этого интерфейс выглядит чище и строже.
Переменные индикации отличаются визуально от уставок. Кнопки и
тумблеры не наши, они стандартные от Scada и их изменить было
нельзя.
2018
Это крупный логистический центр в Московской Области, оснащенный
разными системами, за работой которых нужно следить, управлять и
анализировать. Этот клиент дал мощный толчок в развитие, в том
числе и с точки зрения пользовательского интерфейса, мы по сей день
проводим здесь много работ, применяя новые алгоритмы управления и
аналитики. К этому объекту я еще буду возвращаться в этой статье,
но пока о том, как он повлиял на разработку интерфейса.
Основное отличие подхода к разработке этого интерфейса от
предыдущих, это то, как рисуется вся статика. До этого интерфейс
собирался по частям в среде разработки для панелей и в Scada
системе, это очень усложняет процесс, особенно, выравнивание
объектов. Здесь же вся статика делается в графическом редакторе и
подгружается одной картинкой PNG на экран. Сверху накладываются
только переменные и анимация. Это сразу убивает несколько зайцев:
выравнивать и делать отступы можно с большой точностью, скорость
загрузки страниц увеличивается, так как нужно меньше информации
подгружать из памяти, уменьшается нагрузка на процессор.
С точки зрения дизайна, тут появилось много нового. Появился не
стандартный шрифт GothamPro, цвета теперь не рандомные, а подобраны
из палитр Material Design, появились кратные отступы и сетка.
Объекты теперь выровнены все относительны друг друга. Поля
индикации и ввода значения уже стали существенно различаться, к
этому быстро привыкаешь и пользоваться становится удобно.
Что осталось от прежних интерфейсов? Структура меню, она не
поменялась, иконки стали меньше и аккуратнее, теперь они гармонично
вписались в общую стилистику. Иконки на главном окне с мнемосхемой
остались прежние, но сама мнемосхема слегка упростилась и стала
чуть более плоской. Это был последний год использования этих иконок
и 3Д элементов в целом.
В целом, на подготовку этого интерфейса ушло много времени, и
результат получился довольно неплохим. По-прежнему остались не
доработаны подписи к переменным, например, не хватает градусов и
герцев в обозначениях.
Первое видео было с панели оператора 7 дюймов, которая
установлена на дверце шкафа управления, разработка дизайна
интерфейса началась с нее, дальше будут экраны с мониторов системы
диспетчеризации.

Приточно-вытяжная вентиляция, экран с
диспетчерской, 25 дюймов

Принципиальная схема котельной, монитор с
диспетчерской 25 дюймов

Обзорная схема инженерных систем
логистического центра, 25 дюймов
Мнемосхемы с панели почти без изменений перешли на широкий экран
монитора. Так как подложка вся рисуется в графическом редакторе, то
переверстать ее с одного разрешения на другое без сильных изменений
довольно просто. Кое-какие элементы использовались из готовых
библиотек. Кстати, здесь с обозначениями намного все лучше и
понятнее.
Что касается главного экрана, то здесь реализован "карточный"
интерфейс. Смысл его в том, чтобы структурировать информацию по
системам, на каждую сделать свою карточку и разместить ее на схеме
здания. Если систем много, можно разделить их по нескольким
экранам, если не много, то можно все показать на одном экране и
отделить разные схемы цветами. На карточке нужно отображать только
самые основные параметры, которые влияют на работоспособность
установки и которые можно сравнивать между собой. Для вентиляции
наиболее важными параметрами являются: статус работы, наличие
аварий, режим зима/лето, температура канала, помещения и обратной
воды. Дополнительно стараемся отображать обороты вентилятора,
процент открытия клапана и задание уставки температуры. Эти
значения позволяют быстро оценить стабильность работы вентсистем и
теплоснабжения установок, не переходя к схемам каждой системы
отдельно. Очень удобно на одном экране сравнивать параметры работы
разных систем. Если, например, наблюдается недогрев по многим
системам, значит есть проблемы с теплоснабжением из котельной.
У нас есть объекты, которые имеют один этаж и там удобно все
карточки систем размещать на планировке здания, привязывая к их
реальному местоположению на плане. Есть объекты в 4-5 этажей, и
здесь становится сложнее структурировать карточки. Можно разделить
экран на 4 равных части и на каждом отобразить свой этаж с
системами. Можно сделать 4 экрана, на каждом свой этаж с нанесенным
на нем системами, но здесь могут быть нюансы, как правило, большая
часть систем располагается на -1 этаже и на последнем или кровле,
что приводит к сильному дисбалансу. Мы пробовали разные варианты,
расскажу об этом чуть дальше в статье.
2019

Приточно-вытяжная установка, панель оператора 7
дюймов

Менюшка, панель 7 дюймов
В начале этого года был важный клиент, которому мы поставили
шкафы управления климатом и они уехали работать в Румынию.
Здесь мы опять решили пересмотреть дизайн интерфейса и внести
что-то новое. Наконец-то полностью ушли от 3Д, теперь у нас все
плоское. Идея была уйти от 3Д, тем самым убрать лишние не
информативные элементы со схемы, освободить ценное место и
структурировать информацию не по графическим элементам, а по
карточкам. Раньше, чтобы показать информацию о теплоснабжение
установки (работа насоса, клапана, температура обратной воды) нужно
было нарисовать целый узел с трубами, насосом, перемычками и
прочим, это занимает много места и несет мало информации. Теперь
вся эта информация находится в карточке "нагрев", точно так же
структурированы и другие карточки систем. Такая структура дает
унификацию интерфейса, если появится система, например, с
дополнительным увлажнением или ступенью нагрева, то мы просто
добавим новую карточку с нужной информацией, при этом интерфейс
будет выглядеть одинаково преемственно на разных устройствах и
разрешениях. Точно так же легко унифицируются и различные системы,
вентиляция, отопление, освещение, энергетика, водоснабжение и так
далее, все это легко приводится к одному стандарту и упрощает
взаимодействие пользователя.
Менюшка не поменялась, переходит из года в год без изменений.
Цвета стали более темными, вернулась обводка некоторых элементов,
цвет акцента остался синим, поменяв немного оттенок. Переменные
больше не обрамляются прямоугольником или обводкой, без рамок они
стали просторнее.
В целом, этот интерфейс получился не очень удачным и
гармоничным, но он заложил сразу несколько важных правил.
-
Освобождаем интерфейс от всего лишнего, уменьшаем количество
статических элементов, убираем все 3Д. Структурируем содержание по
карточкам или вкладкам, оставляем больше места для динамических
значение.
-
Наводим порядок в цветах для удобства взаимодействия
пользователя с интерфейсом. Оттенки темного цвета используются для
фона, полей и заголовков, серым обозначаются подписи и весь текст в
целом. Белый это переменные и все динамические значения. Яркий
синий это цвет акцента, им обозначаются все элементы, с которыми
пользователь может взаимодействовать, кнопки и уставки. И
стандартные цвета: зеленый, желтый и красный, отвечают за состояние
и индикацию.

Диспетчеризация торгово-развлекательного
центра, окно вентустановки, монитор 32 дюйма

Сводное окно венткамеры, монитор 32 дюйма

Главный экран с обзорной схемой
вентустановок, монитор 32 дюйма.
В этом же году реализовали одну из самых масштабных задач с
точки зрения количества передаваемой информации. Это
торгово-развлекательный центр в Московской Области, оснащенной
большим количеством инженерных систем. Остановлюсь только на
интерфейсе систем вентиляции.
В этот интерфейс перетекли почти все наработки из предыдущего
примера, но при этом я считаю этот интерфейс один из самых
гармоничных и удачных. Здесь опытным путем нащупал палитру оттенков
темно-синего цвета, который наиболее комфортный для глаз, эту
палитру используем по сей день, она не меняется. Цвета стали лучше,
ушли полностью тени, обводка стала более аккуратной, за счет этого
интерфейс стал выглядеть лучше.
Здесь очень удачно планировка ТЦ вписалась в разрешение Scada
системы примерно 1920 х 980 рх., это позволило расположить максимум
полезной информации с привязкой к физическому местоположению. Так
как систем много (около 150 штук) то лучший вариант разбить их по
венткамерам, где находятся щиты управления, отобразить системы как
название и подкрашивать его в зависимости от состояния. Серый
выведен из эксплуатации, белый стоянка, зеленая работает, желтая
требует обслуживания, красный авария. Дальше архитектура строится
так: при клике на венткамеру открывается табличный вид связанных
систем с их основными параметрами. При клике на название системы
уже откроется мнемосхема со всеми доступными параметрами и
настройками.
Хотя здесь есть некоторые не доработанные моменты: кнопки
сброса, индикаторы аварии, зима/лето, все равно это один из самых
удачных результатов работ за все время работы. На этом объекте мы
провели много дней и ночей и все это время пользовались своей же
работой, и по своим субъективным ощущениям, эксплуатировать
технологические системы в этом интерфейсе максимально
комфортно.
2020

Приточно-вытяжная установка с
увлажнением, монитор 25 дюймов

Приточно-вытяжная установка с
увлажнением, монитор 25 дюймов

Обзорная схема системы диспетчеризации,
медицинский центр, монитор 23 дюйма

Обзорная схема системы диспетчеризации
ТРЦ Рассвет, Москва, монитор 23 дюйма

Мнемосхема приточно-вытяжной установки.
Так, ну в этом году продолжилось логическое развитие интерфейсов
с некоторыми экспериментами. Расскажу по порядку.
Квадратные закругленные плашки на мнемосхеме превратились в
круг. Если проследить за этими плашками, то можно увидеть, как они
из квадрата медленно превращаются в круг. Круглый элемент выглядит
на схеме лучше, он визуально освобождает больше пространства на
самой схеме, делает ее лаконичнее, но при этом вылезает сразу
несколько проблем. Рассмотрим водяной калорифер. У него есть
несколько параметров, которые обязательно нужно показать на схеме:
температура обратной воды, процент открытия клапана, статус работы
насоса. Желательно еще показать статус термостата защиты от
разморозки и разместить какую-то иконку, чтобы отличить узел
нагрева от узла охлаждения. Как все это поместить в круг, чтобы при
этом информация считывалась и не рушилась вся концепция придумать
на этом этапе я не смог. Поэтому, на примерах сверху было два
решения. Первое, убрать часть информации в нижнюю плашку меню или в
другое место. Второе, просто сделать подложку под нагрев
значительно больше, чем другие круглые элементы схемы и разместить
все в ней. Оба варианта не самые лучшие, но иначе сделать не
получалось. При этом все равно круглые элементы выглядят лучше и
перспективнее прямоугольных.
На обзорной схеме применяется все тот же карточный интерфейс,
более яркий и с новыми крупными иконками. Здесь тот случай, когда
здание в несколько этажей и с раскиданными инженерными системами.
После разных прикидок и вариантов, пришли к выводу, что удобнее
сделать разрез здания с сохранением очертания фасада и разместить
все карточки по этажам. На примерах вверху два разных объекта, на
одном удалось разместить все системы на схеме, в другом их
значительно больше, поэтому сделали несколько вкладок с разбивкой
по назначению систем. Дополнительно решили сделать разные цвета и
на бирках карточек, чтобы быстрее можно было найти нужную
установку. Например, все технологические вентустановки имеют рыжую
бирку.
Если вы дочитали до этого места, то скорее всего обратили
внимание, что впервые появился светлый интерфейс =). Появилась
очень интересная идея сделать универсальный интерфейс с темной и
светлой темой и переключать его либо автоматически от времени
суток, либо вручную. Реализовали эту идею так: подложки на 95
процентов прозрачные с небольшим оттенком серого, статические
элементы имеют цвета не сильно контрастирующие на темном и светлом
фоне, переменные имеют подобранный серый цвет, больше
контрастирующий на темном и светлом фоне. По сути, мы только меняем
цвет фона с белого на темно серый, а все элементы остаются без
изменения. С точки зрения работы Scada системы процесс максимально
простой, подмена одного фона на другой, без замены других
элементов, это не перегружает процесс работы и отрисовки. У такого
решения есть минус, сложно подобрать цвета одинаково правильно
отображающиеся тут и там, от этого переменные немного теряются на
общем фоне. Есть вариант вместе с фоном менять скриптами и цвета
переменных и других элементов, но не понятно насколько это может
загрузить процесс отрисовки.
Идея с изменяемой темой интерфейса кажется очень перспективной и
полезной для эксплуатации, так как диспетчерские пункты
круглосуточные, днем может светить солнце в окно, а ночью будет
свет выключен вообще. Несмотря на то, что было потрачено много
времени на эту концепцию и она была полностью готова, в релиз она
не пошла, и насколько это полезная функция мы пока не узнали.
2021

Главное окно системы диспетчеризации,
логистический центр, МО

Мнемосхема приточно-вытяжной установки

Экран работы вентустановки воздушного
отопления

Обзорная схема работы котельной
В этом году получилось сделать еще один шаг вперед и улучшить
то, что было. Полностью переработанные плашки с элементами, теперь
они содержат больше информации в себе, гармонично вписываются в
общую концепцию, задают общую стилистику мнемосхемы, дают больше
универсальности и могут быстро информировать о своем состоянии. Я
думаю, это лучшее, что можно сделать с мнемосхемой. Рассмотрим
пример водяного нагревателя и вентилятора.
В водяном нагревателе, как ранее уже писал нужно показать
температуру обратной воды, процент открытия клапана, статус работы
насоса и аварийный сигнал. Процент открытия клапан нагрева наиболее
важное значение, поэтому я поместил его в центр и сделал большим
шрифтом. Помимо самого значения, вокруг круглой плашки есть
заполняющая его линия по кругу, она двигается по часовой стрелке и
заполняет обводку круга пропорционально значению от 0 до 100.
Температура обратной воды показан в круге, но уже меньшим шрифтом,
и она поменяет свой цвет, если значение будет слишком низким. Если
произойдет авария по термостату или по низкой температуре обратной
воды, то вся обводка круга загорится красным цветом, инженеру будет
понятно, что авария пришла именно с нагрева. Помимо этого добавил
еще один режим "прогрев", в момент запуска вентиляции в зимнем
режиме, перед пуском установки открывается клапан и прогревается до
заданной температуры, в этот момент обводка плавно мерцает рыжим
цветом. В стоянке в зимнем режиме обводка окрашена в белый цвет,
означает, что насос работает, зимний режим включен, клапан
поддерживает заданную температуру обратки. В летний период обводка
становится серой и "выключается", тем самым мы понимаем, что
водяной нагрев не активен.
С вентилятором ситуация аналогичная, внутри плашки мы можем
показать текущую скорость в герцах или процентах, включен
автоматический режим или ручной, можем показать состояние реле
перепада давления, если оно есть. Обводка здесь состоит из двух
секторов, они вращаются по часовой стрелке (против часовой на
вытяжке), если вентилятор работает. Скорость вращения
пропорциональная текущим герцам. Если с вентилятора приходит
авария, то сектора окрасятся в красный цвет. В стоянке сектора
имеют белый цвет.
С точки зрения Scada системы, мы имеем набор кадров (в
нагревателе больше 100 кадров), которые меняются в зависимости от
условий. Никаких GIF анимаций и наложенных слоев, отрисовка и
реакция происходит мгновенно.
В остальном изменений мало и все они носят косметический
характер. Изменился тумблер, доработаны иконки на обзорной схеме,
изменились заголовки окошек меню, раньше у них была полоска
контрастного цвета с надписью, теперь остался только текст за
пределами подложки. Меню стали просторнее, отступы стали больше.
Острых углов почти не осталось, все, что можно было скруглить -
скруглили. Уделили внимание подписям и подсказкам, обозначения
везде корректные и переменные уже не перепутать.
За все время работы я старался создать пользовательский
интерфейс максимально удобный для клиента. Интерфейс должен быть не
перегружен информацией, простой и удобный, современный и стильный.
По итогу, на сегодняшний день, считаю, что с этой задачей мы
справились.
2022
В следующий раз, я думаю, что создам новый проект и начну
рисовать заново. Скорее всего, переработаю немного цветовую
палитру, сетку и иконки. Обязательно придумаю универсальный переход
с темной темы на светлую.
Надеюсь, вы нашли в статье что-то полезное для себя. Буду рад,
если оставите свою критику и комментарии, напишите, какой интерфейс
больше понравился вам и почему.


 Вот что определитель думает про общий номер Альфы...
Вот что определитель думает про общий номер Альфы...
 ...а вот так определитель пишет про номер
Тинькофф Банка
...а вот так определитель пишет про номер
Тинькофф Банка

 Подключаем
сигнальные линии
Подключаем
сигнальные линии
 Силовой
шкаф до расключения
Силовой
шкаф до расключения
 Основное окно секции освещения
Основное окно секции освещения
 Окно с настройками
Окно с настройками
 Временные тренды
Временные тренды
 Отчет за выбранное время
Отчет за выбранное время
 Отчет за выбранное время
Отчет за выбранное время















 Фотография: Giorgio Trovato. Источник: Unsplash.com
Фотография: Giorgio Trovato. Источник: Unsplash.com
") Фотография: Paul Downey. Источник:
Flickr.com (CC BY 2.0)
Фотография: Paul Downey. Источник:
Flickr.com (CC BY 2.0)















.") Источник фото: TactoTek, финская
компания, которая развивает технологию IMSE (In-Mold Structural
Electronics).
Источник фото: TactoTek, финская
компания, которая развивает технологию IMSE (In-Mold Structural
Electronics).
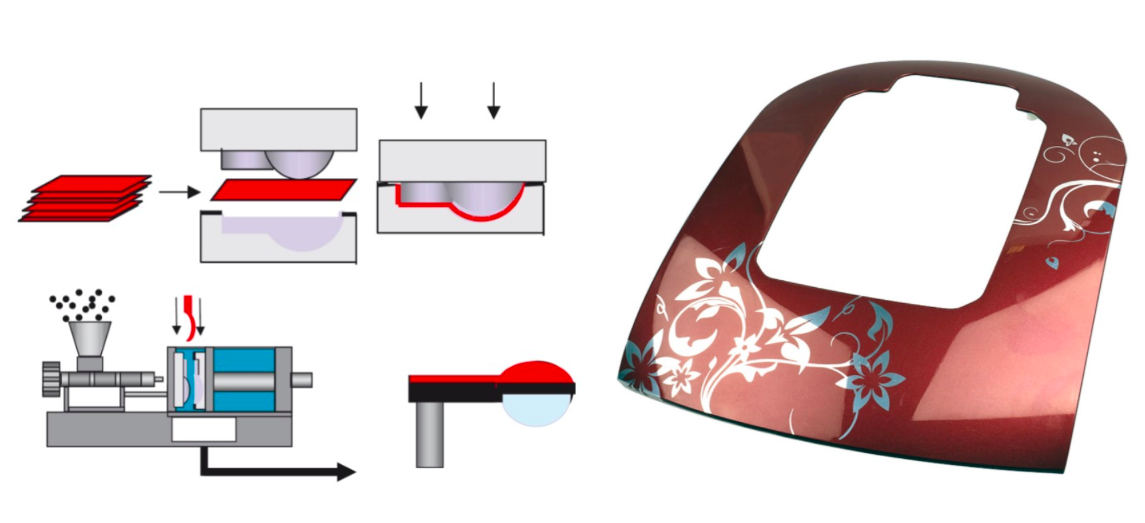



 Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont
Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont
Источник изображений: Functional Ink
Systems for In Mold Electronics by DuPont
 Источник фото: Functional Ink Systems for
In Mold Electronics by DuPont
Источник фото: Functional Ink Systems for
In Mold Electronics by DuPont

















 Библиотечная иерархия
Библиотечная иерархия











































 Модель из статьи в Harvard Business Review
Модель из статьи в Harvard Business Review
 Фото Charles Deluvio, площадка Unsplash
Фото Charles Deluvio, площадка Unsplash

 Amazon на главной странице дает
пользователям много вариантов
Amazon на главной странице дает
пользователям много вариантов
 Отличная иллюстрация информационного
запаха от NN Group
Отличная иллюстрация информационного
запаха от NN Group
 Да, иногда найти необходимое бывает не
так уж и просто! Фото Daniel Mingook Kim, площадка Unsplash
Да, иногда найти необходимое бывает не
так уж и просто! Фото Daniel Mingook Kim, площадка Unsplash
 Missguided использует эту возможность и
помогает найти нужное или открыть для себя что-то новое
Missguided использует эту возможность и
помогает найти нужное или открыть для себя что-то новое Vero Moda тоже хорошо справляется с
задачей: заметное поле поиска и популярные категории
Vero Moda тоже хорошо справляется с
задачей: заметное поле поиска и популярные категории Birchbox также помогает открыть что-то новое для себя
Birchbox также помогает открыть что-то новое для себя
 Фото
Fab Lentz, площадка Unsplash
Фото
Fab Lentz, площадка Unsplash





 Все изображения принадлежат институту CXL
Все изображения принадлежат институту CXL
 Изображение институт CXL
Изображение институт CXL Изображение институт CXL
Изображение институт CXL
 Фото
Balzs Ktyi, площадка Unsplash
Фото
Balzs Ktyi, площадка Unsplash
 Фото Sebastian Herrmann, площадка Unsplash
Фото Sebastian Herrmann, площадка Unsplash
 Фото Amlie Mourichon, площадка Unsplash
Фото Amlie Mourichon, площадка Unsplash
 Изображение UsabilityHub
Изображение UsabilityHub


 Соревнование / Irina Salvart
Соревнование / Irina Salvart
 Наброски / Irina Salvart
Наброски / Irina Salvart
 Ты и твой парень-геймер / Irina Salvart
Ты и твой парень-геймер / Irina Salvart
 Всегда за / Irina Salvart
Всегда за / Irina Salvart
 История
успеха / Irina Salvart
История
успеха / Irina Salvart
 Дизайнер из 90-х / Irina Salvart
Дизайнер из 90-х / Irina Salvart











 Да, эти иллюстрации с разных сайтов:
скриншоты из Slack, Markup и Google Покупок.
Да, эти иллюстрации с разных сайтов:
скриншоты из Slack, Markup и Google Покупок.
 Скриншот YouTube
Скриншот YouTube