

Журналы все чаще отзывают научные статьи, потому что оказывается, что написаны они не теми, кем заявлено. Необходимо выработать более эффективные способы решения проблемы, в противном случае мы рискуем полностью утерять общественное доверие к науке.
Занятие наукой подразумевает поиск знаний об окружающем мире при помощи строгой логики и проверки каждого предположения. По результатам таких поисков исследователи описывают важные открытия в работах и отправляют их издателям для возможной публикации. После экспертной оценки, в ходе которой другие ученые подтверждают достоверность изложенного материала, журналы публикуют работы для ознакомления с ними общественности.
В связи с этим многие небезосновательно верят, что опубликованные работы весьма надежны и отвечают высоким стандартам качества. Вы можете ожидать встретить какие-то незначительные оплошности, упущенные в процессе ревью, но явно не крупные нестыковки. Ведь все-таки это наука!
Как ни печально, но в подобном предположении вы ошибетесь. Реальная и точная наука существует, но и в этой области наблюдается тревожное количество фиктивных исследований. Причем за последние несколько лет их объем увеличивается с невероятной скоростью, о чем свидетельствует все более частый отзыв научных статей от публикаций.
Фиктивная наука
На данный момент практикуется ряд приемов, которые угрожают подрывом легитимности научных исследований в целом. К ним относятся выдумывание авторов, а также указание соавторства никак не связанных с исследованием ученых и даже более гнусные приемы вроде заваливания журналов материалами из низкосортного бреда, сгенерированного ИИ.
Этот процесс аналогичен отзыву товаров в магазинах. Если ранее проданный товар по какой-то причине оказался плох или опасен, то магазин обязан отозвать его и попросить покупателей его не использовать. Таким же образом журнал может отозвать опубликованную работу, которая в ретроспективе оказалась фиктивной.
Конечно же, иногда статьи отзываются по причине искренней ошибки автора. Однако более, чем в половине случаев причиной оказываются академические нарушения или откровенная подделка. Вплоть до начала последнего десятилетия подобные явления обычно ограничивались фальсификацией исследователями экспериментальных данных или искажением результатов экспериментов в угоду их теории. Однако, чем больше усложняется технологический мир, тем более запутанными становятся и средства мошенничества в нем.
Одним из простых решений может стать простое игнорирование ложных работ. Но проблема в том, что их, как правило, сложно определить. К тому же, каждый отзыв статьи из публикации в некоторой степени губит репутацию журнала. А если такое будет происходить регулярно, то и общественная вера в научные исследования сойдет на нет. Следовательно, научное сообщество должно уделить этой проблеме серьезное внимание.
Camille Nos
Часть этой проблемы смоделирована намеренно. К примеру, Camille Nos никак не связано с ИИ, но все равно заслуживает упоминания. Созданное в марте 2020 года, Nos уже выступило соавтором более, чем 180 работ в таких разносторонних областях, как астрофизика, компьютерная наука и биология.
Я использовал оно, потому что Nos не является реальным человеком. На деле это псевдо-личность, созданная французским движением в защиту науки RogueESR. В качестве первого имени было взято французское гендерно-нейтральное Camille, а в качестве фамилии слияние греческого слова , означающего разум/познание, и французского слова nous, означающего мы.
Nos была создана в ответ на новый, вызвавший бурную критику, закон (источник на французском) по реорганизации академических исследований во Франции. Несмотря на то, что задачей закона было улучшение исследовательской деятельности, его противники считают, что ввиду устанавливаемых им требований рабочие места ученых окажутся в шатком положении и будут зависеть от внешнего финансирования. В частности, согласно новому закону, финансирование ученых должно соответствовать их прежним заслугам, хотя открытия, как правило, совершаются на уровне сообщества коллективно.
Чтобы открыто обозначить эту проблему, многие исследователи выбрали добавлять в качестве соавторов Nos. Однако журналы и научные рецензенты, которые отвечали за проверку таких работ, не всегда ставились в известность о том, что Nos реальным человеком не является.
Несмотря на то, что исследовательская составляющая этих работ пока что внушает доверие, здесь возникает обеспокоенность тем фактом, что в качестве соавтора можно легко добавить псевдо-личность, у которой даже нет удостоверения. Безусловно сама затея подчеркивать общественные усилия такими авторами, как Nos является похвальной, но мысль о том, что сегодня ученых можно буквально рожать из воздуха, весьма настораживает.

Усилия сообщества должны быть стандартизированы, но пока для этого нет системы
Указание авторов там, где они не участвовали
Тем не менее проблема проявляется не только в недостатках системы экспертной оценки и научной среды. Случаи фейкового соавторства особенно участились в работах по теме ИИ. Это мошенничество включает практику внесения в соавторы широко известных ученых, даже без их уведомления или согласия. Еще один способ это добавление фиктивного соавтора, такого как Camille Nos, но уже с целью симулирования международного сотрудничества или вызова более широкого научного дискурса.
Помимо привнесения иллюзии международного сотрудничества, указание фиктивных авторов с респектабельными именами может повысить авторитетность работы. Многие ученые, прежде чем читать или цитировать таких авторов в своей работе, будут искать их имена в Google. При этом участие в соавторстве сотрудника престижного института может подтолкнуть их к более пристальному изучению работы, особенно если она еще не проходила экспертное ревью. Престиж института в таком случае может служить неким заместителем достоверности на период оценки работы экспертами. А на такую оценку порой уходят долгие месяцы.
Сложно сказать, сколько лже-авторов на текущий момент уже внесено в публикации. Одна из причин в том, что некоторые ученые могут предпочесть игнорировать указание собственной фамилии в работе, которую они не писали. Это особенно верно для случаев, когда содержимое такой работы нельзя назвать плохим (как и хорошим), а на судебные разбирательства может уйти много денег и времени. Более того, сейчас не существует ни одного стандартного метода для проверки идентичности ученого перед публикацией его работы, что позволяет фиктивным авторам проскальзывать налегке.
Все эти проблемы показывают необходимость внедрения процесса верификации ID. Официально ничего подобного мы на данный момент не имеем, и это должно быть стыдно. В эпоху, когда каждый банк может верифицировать ваш ID онлайн и сопоставить его с лицом на вашей веб-камере, наука даже не способна защитить от мошенничества своих наиболее ценных участников.

Когда речь идет о написании научных работ, то путь мысли старого-доброго человеческого ума пока еще превосходит налучший ИИ
Алгоритмы плохие писатели
В 1994 году физик Алан Сокал решил написать фейковую статью по какой-то гуманитарной теме и отправить ее в журнал. Статью приняли, хотя никто, включая самого автора, не понял, о чем она была. Это не только смехотворно, но также показывает, насколько рецензенты могут облениться. В этом случае они, по сути, одобрили бессмысленную статью.
Аналогичным образом в 2005 году трое студентов, изучавших компьютерные науки, решили приколоться над научным сообществом, разработав программу SCIgen. Она генерирует абсолютно бессмысленные работы с графами, иллюстрациями и цитатами, приправленные множеством заумных слов из компьютерной науки. Одна из таких статей даже была принята к участию в конференции. Более того, в 2013 году различными издателями было отозвано 120 работ, когда вскрылось, что написала их SCIgen. За 2015 год сайт программы все еще зарегистрировал около 600 000 посещений.
К сожалению, фейковые статьи генерируются не только в качестве шутки или студенческого прикола. Целые компании зарабатывают деньги, создавая бредовые статьи и отправляя их хищническим журналам, которые такие работы принимают просто потому, что берут за это комиссию. Подобные компании, иначе именуемые бумажными фабриками, вырабатывают все более и более изощренные методы.
Несмотря на совершенствование техник обнаружения подделок, эксперты небезосновательно остерегаются, что такие бессовестные деятели, отточив свое мастерство на низкосортных журналах, могут рискнуть переключиться на авторитетные. Это способно привести к своеобразной гонке вооружений между бумажными фабриками и журналами, которые не хотят публиковать бредятину.
Конечно, это не все, и на горизонте маячит еще один вопрос: Как долго написанием научных работ будут заниматься только люди? Может ли случиться так, что через 10 или 20 лет ИИ-алгоритмы станут способны автоматически анализировать обширные объемы литературы и делать собственные заключения в новой работе, соответствующей высшим научным стандартам? Как тогда мы будем отдавать должное этим алгоритмам или их создателям?
Хотя сегодня мы пока имеем дело с намного более простыми вопросами: Как выявить работы, написанные относительно несложными алгоритмами, и не несущие никакой смысловой нагрузки? Что с ними в итоге делать? Помимо добровольных усилий и принуждения лже-авторов отзывать свои работы, научное сообщество имеет поистине мало ответов на эти вопросы.

Большинство журналов остро нуждаются в обновлении систем безопасности для отслеживания фиктивных работ
Противодействие фальшивой науке
Большинство журналов, дорожащих своей заслуженной репутацией, по крайней мере требуют от желающих опубликовать свои работы верификацию по электронной почте. Вот, к примеру, система верификации журнала Science. Но несмотря на это, создать фейковую почту и пройти такой процесс проверки достаточно просто. Подобный вид мошенничества по-прежнему распространен, что подтверждается большим количеством работ, ежегодно отзываемых даже из престижных журналов. Это лишь доказывает, что нам необходима более строгая система контроля.
Один из эффективных подходов идентификации ученых это ORCID. По сути, с помощью этой системы, каждый исследователь может получить уникальный идентификатор, который затем будет автоматически привязываться к хронологии его деятельности. Применение ORCID при экспертной оценке журналов и в процессе публикации существенно усложнит создание фиктивных личностей или использование имен исследователей без их согласия.
Несмотря на то, что это очень многообещающая инициатива, ни один серьезный журнал еще не ввел обязательное получение авторами идентификаторов из ORCID или иных систем. Я считаю, что подобное бездействие позорно, ведь таким образом можно с легкостью решить проблему.
Наконец, в данном контексте может помочь сам искусственный интеллект. Некоторые журналы развертывают модели ИИ для обнаружения фиктивных работ. Однако пока что, издатели еще не пришли к согласию по единому стандарту. Как следствие, журналы, которым недостает ресурсов или опыта, не могут применять меры того же уровня, что и авторитетные издания.
Это расширяет разрыв между журналами высокого и низкого уровня и, лично для меня, является очевидным подтверждением того, что все заинтересованные издания должны объединиться и найти способ распределить ресурсы для борьбы с мошенничеством. Конечно же, более популярные журналы могут получать выгоду за счет отставания конкурентов, но только в краткосрочной перспективе. Если же заглянуть дальше, то преобладание числа журналов с низкими стандартами может снизить доверие к научным публикациям в целом.
И речь не о том, что исследователи и научные журналы сидят и бездействуют вместо того, чтобы отслеживать лже-авторов. Отдельные издания действительно проделывают в этом направлении очень многое. Но, если одни журналы имеют для этого средства, а другие нет, то получается, что публикуются они не на равных правилах игры. К тому же, мошенники всегда смогут нацелить свои фейковые статьи на журнал с низким бюджетом.
Именно поэтому в данном случае для отслеживания бумажных фабрик и определения идентичности всех их авторов необходим коллективный подход.
Помимо науки: все больше фейковых новостей
Думаю, ни для кого не секрет, что фейковый контент свойственен не одной только науке. Всего несколько лет назад в разгар эпохи Трампа выражение фейковые новости уже звучало как хит сезона. А с тех пор методы генерации контента с целью влияния на общественное мнение стали только изощреннее. При этом они весьма похожи на методы, применяемые в научных работах.
К примеру, в различных консервативных СМИ было очевидно, что авторами обзорных статей являются фейковые журналисты. Их фотографии генерировались ИИ-алгоритмами, а аккаунты LinkedIn и Twitter были абсолютно вымышленными, и до сих пор неизвестно, кто на самом деле стоял за этими статьями.
Существуют также несколько генераторов новостных статей, которые упрощают создание фейковых аннотаций. Несмотря на то, что опытного фактчекера таким способом не проведешь, среднего пользователя Facebook подобный материал может зацепить настолько, что он даже поделится им с друзьями.
Именно поэтому я доверяю только новостям и научным данным из проверенных источников, а также контенту, который могут самостоятельно перепроверить на истинность. Другие источники я полностью отвергаю, потому что знаю, что большинство из них находится в диапазоне от простительной ошибки до абсолютного вымысла.
Еще несколько лет назад я не придерживался такой позиции, как и люди, меня окружающие. Доверие к новостям существенно подкосилось, и я даже не представляю, каким образом его можно вернуть. Сегодня то, что уже давно происходило с новостями, начало происходить с наукой. Очень плохо, что найти правду о происходящем в мире становится все сложнее. Но если пошатнуться основы самого человеческого знания, то это уже будет куда большее бедствие.
Несмотря на то, что споры вокруг фейковых новостей затихли после выборов 2020 года, тема далеко не закрыта. Поскольку инструменты для подделывания контента все больше и больше совершенствуются, я считаю, что в ближайшие годы этот вопрос еще разгорится очередной волной внимания.
Хочется верить, что к тому времени мы уже достигнем согласия на тему того, как противостоять фейковому контенту и фейковым исследованиям.



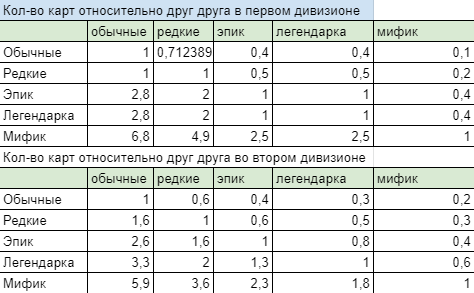


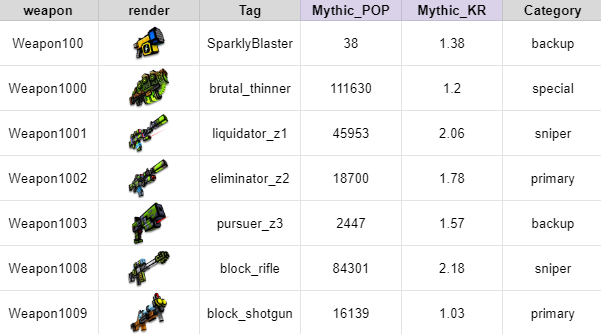


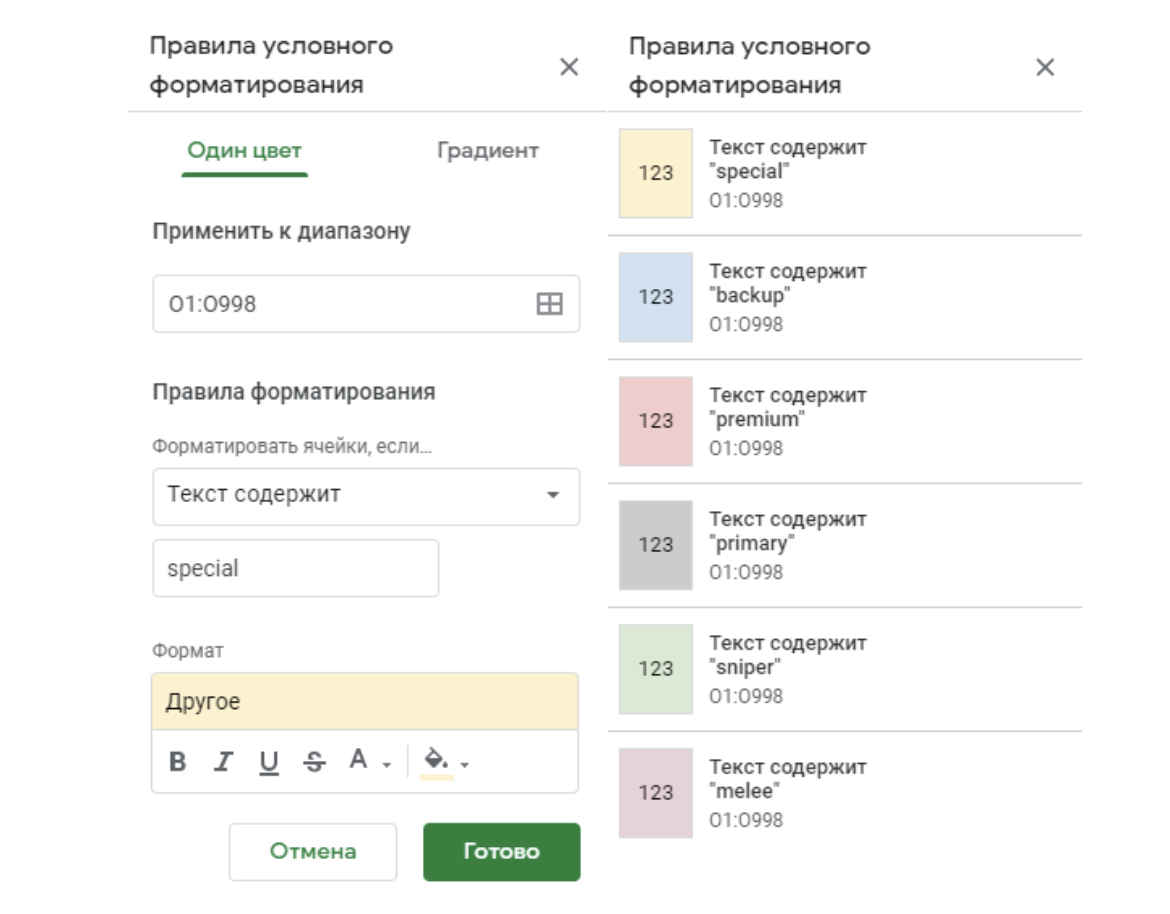
 График популярности оружия
График популярности оружия







































































 Интерфейс ruGTP-3
Интерфейс ruGTP-3
 C первого захода сеть отказалась работать...
C первого захода сеть отказалась работать... Со второго выдала полотно текстовой
бредятины...
Со второго выдала полотно текстовой
бредятины... Третий заход тоже бредятина, хоть полотно
и покороче...
Третий заход тоже бредятина, хоть полотно
и покороче...
 Тогда я решил, будто продаю свежие цветы
в Хабаровске и пишу текст для этих целей. А сеть сказала, что в
Хабаровске можно есть еще и животных. Жесть. По-моему, это провал.
Тогда я решил, будто продаю свежие цветы
в Хабаровске и пишу текст для этих целей. А сеть сказала, что в
Хабаровске можно есть еще и животных. Жесть. По-моему, это провал.
 Текст на главном экране: Представляем
конец страха чистого листа. С инструментами для автоматизации
креатива от COPY.AI вы сможете генерировать маркетинговые тексты за
секунды. И призыв начать 7-дневный пробный период.
Текст на главном экране: Представляем
конец страха чистого листа. С инструментами для автоматизации
креатива от COPY.AI вы сможете генерировать маркетинговые тексты за
секунды. И призыв начать 7-дневный пробный период.
 Скриншот кабинета
Скриншот кабинета
 цветы. Продаю их офисным работникам из Хабаровска со скидкой 30% (организую распродажу в честь дня города).") Написал описание товара (Product
Description) цветы. Продаю их офисным работникам из Хабаровска со
скидкой 30% (организую распродажу в честь дня города).
Написал описание товара (Product
Description) цветы. Продаю их офисным работникам из Хабаровска со
скидкой 30% (организую распродажу в честь дня города).
 Получил 7
вариантов текста.
Получил 7
вариантов текста.
